SQLD 2과목 정리 PART2. SQL 활용
9. 서브쿼리
● 서브쿼리
- 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 말함
- 반드시 괄호로 묶어야 함
ex) SELECT 안에 SELECT문 / INSERT, UPDATE, DELETE 안의 SELECT문
● 서브쿼리 사용 가능한 곳
- SELECT절
- FROM절
- WHERE절
- HAVING절
- ORDER BY절
- 기타 DML(INSERT, DELETE, UPDATE)절
** GROUP BY절 사용 불가
●서브 쿼리 종류
- 동작하는 방식에 따라
- ) UN-CORRELATED(비연관) 서브쿼리
- 서브쿼리가 메인쿼리 컬럼을 가지고 있지 않은 형태의 서브쿼리
- 메인쿼리에 서브쿼리가 실행된 결과 값을 제공하기 위한 목적으로 사용
- ) CORRELATED(연관) 서브쿼리
- 서브쿼리가 메인쿼리 컬럼을 가지고 있는 형태의 서브 쿼리
- 일반적으로 메인 쿼리가 먼저 실행된 후에 서브 쿼리에서 조건이 맞는지 확인하고자 할 때 사용
- ) UN-CORRELATED(비연관) 서브쿼리
- 위치에 따라
- ) 스칼라 서브쿼리
- SELECT에 사용하는 서브 쿼리
- 서브쿼리 결과를 마치 하나의 컬럼처럼 사용하기 위해 주로 사용
** 문법
SELECT * | 컬럼명 | 표현식, (SELECT * | 컬럼명 | 표현식 FROM 테이블명 또는 뷰명 WHERE 조건) FROM 테이블명 또는 뷰명;
- 인라인 뷰
- FROM절에 사용하는 서브쿼리
- 서브쿼리 결과를 테이블처럼 사용하기 위해 주로 사용
** 문법
SELECT * | 컬럼명 | 표현식 FROM (SELECT * | 컬럼명 | 표현식 FROM 테이블명 또는 뷰명) WHERE 조건;
- WHERE절 서브쿼리
- 가장 일반적인 서브 쿼리
- 비교 상수 자리에 값을 전달하기 위한 목적으로 주로 사용(상수항의 대체)
- 리턴 데이터의 형태에 따라 단일행 서브쿼리, 다중행 서브쿼리, 다중컬럼 서브쿼리, 상호연관 서브쿼리로 구분
** 문법
SELECT * | 컬럼명 | 표현식 FROM 테이블명 또는 뷰명 WHERE 조건연산자 (SELECT * | 컬럼명 | 표현식 FROM 테이블명 또는 뷰명 WHERE 조건);
- ) 스칼라 서브쿼리
● 서브 쿼리 종류
- 단일행 서브쿼리
- 서브쿼리 결과가 1개의 행이 리턴되는 형태
- 단일행 서브쿼리 연산자 종류
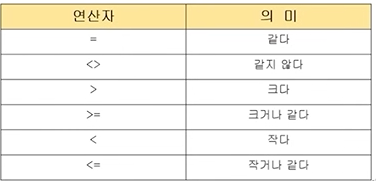
예제) EMP테이블에서 전체 직원의 급여 평균보다 높은 평균을 받는 직원의 정보 출력
정답 :
step 1. 비교대상(전체 직원 급여 평균) 확인
SELECT AVG(SAL)
FROM EMP;
step 2. 메인쿼리의 비교상수 자리에 서브쿼리 결과 전달
SELECT EMPNO, ENAME, SAL
FROM EMP
WHERE EMP > (SELECT AVG(SAL)
FROM EMP;)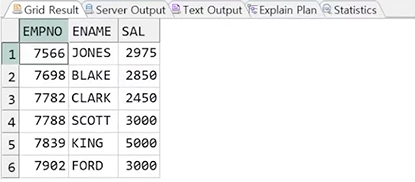
2. 다중행 서브쿼리
- 서브쿼리 결과가 여러 행이 리턴되는 형태
- '=', '>', '<'와 같은 비교연산자 사용 불가(여러 값이랑 비교할 수 없는 연산자들)
- 서브쿼리 결과를 하나로 요약하거나 다중행 서브쿼리 연산자를 사용
** 다중행 서브쿼리 연산자

예제) ALL과 ANY 비교
> ALL(2000, 3000) : 최대값(3000) 보다 큰 행들 반환
< ALL(2000, 3000) : 최소값(2000) 보다 작은 행들 반환
> ANY(2000, 3000) : 최소값(2000) 보다 큰 행들 반환
< ANY(2000, 3000) : 최대값(3000) 보다 작은 행들 반환
예제) 다중행 서브쿼리 연산자 오류(서브 쿼리 결과가 여러개일 경우 = 연산자 대소 비교 불가)
SELECT EMPNO, ENAME, SAL
FROM EMP
WHERE SAL > (SELECT SAL
FROM EMP
WHERE DEPTNO = 10);
** 해결1
서브쿼리 결과를 하나의 행 결과가 되도록 변경
SELECT EMPNO, ENAME, SAL
FROM EMP
WHERE SAL > (SELECT MIN(SAL)
FROM EMP
WHERE DEPTNO = 10);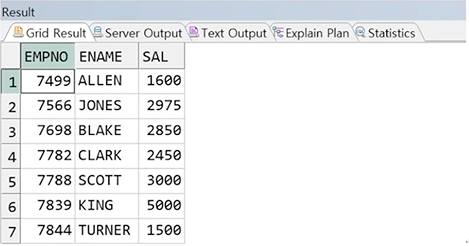
** 해결2
다중행 서브쿼리 연산자로 변경
SELECT EMPNO, ENAME, SAL
FROM EMP
WHERE SAL > ANY(SELECT SAL
FROM EMP
WHERE DEPTNO = 10);
3. 다중컬럼 서브쿼리
- 서브쿼리 결과가 여러 컬럼이 리턴되는 형태
- 메인쿼리와의 비교 컬럼이 2개 이상
- 대소 비교 전달 불가(두 값을 동시에 묶어 대소 비교 할 수 없음)
예제) EMP테이블에서 부서 별 최대 급여자 확인
정답 :
step1. 부서 별 최대 급여 확인
SELECT DEPTNO, MAX(SAL)
FROM EMP
GROUP BY DEPTNO;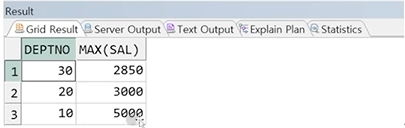
step2. 메인쿼리에 비교 대상으로 서브쿼리 결과 전달
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP
WHERE (DEPTNO, SAL) IN (SELECT DEPTNO, MAX(SAL)
FROM EMP
GROUP BY DEPTNO);
☞ 부서 별 최대 급여가 여러 값이 나오므로 비교시에는 다중행 연산자인 IN을 사용( '=' 사용 시 에러 발생)
● 인라인 뷰(Inline View)
- 쿼리 안의 뷰 형태로 테이블처럼 조회할 데이터를 정의하기 위해 사용
- 테이블명이 존재하지 않기 때문에 다른 테이블과 조인 시 반드시 테이블 별칭 명시
(단독으로 사용하는 경우 불필요) - WHERE절 서브쿼리와 다르게 서브쿼리 결과를 메인 쿼리의 어느 절에서도 사용할 수 있음
- 인라인뷰의 결과와 메인쿼리 테이블과 조인할 목적으로 주로 사용
- 모든 연산자 사용 가능
예제 1) EMP테이블에서 부서 별 최대 급여자를 출력하되, 최대 급여와 함께 출력
정답 :
SELECT E.EMPNO, E.ENAME, E.SAL, I.MAX_SAL
FROM EMP E, (SELECT DEPTNO, MAX(SAL) AS MAX_SAL
FROM EMP
GROUP BY DEPTNO) I
WHERE E.DEPTNO = I.DEPTNO
AMD E.SAL = I.MAX_SAL;
예제 2) EMP테이블에서 부서 별 최대 급여자를 출력하되, 최대 급여와 함께 출력
정답 :
SELECT E.EMPNO, E.ENAME, E.SAL, I.AVG_SAL
FROM EMP E, (SELECT DEPTNO, MAX(SAL) AS AVG_SAL
FROM EMP
GROUP BY DEPTNO) I
WHERE E.DEPTNO = I.DEPTNO
AMD E.SAL > I.AVG_SAL;
● 스칼라 서브쿼리
- SELECT절에 사용하는 쿼리로, 마치 하나의 컬럼처럼 표현하기 위해 사용 (단, 하나의 출력 대상만 표현 가능)
- 각 행마다 스칼라 서브쿼리 결과가 하나여야 함(단일행 서브쿼리 형태)
- 조인의 대체 연산
- 스칼라 서브쿼리를 사용한 조인처리 시 OUTER JOIN이 기본(값이 없더라고 생략되지 않고 NULL로 출력)
예제) EMP의 각 직원의 사번, 이름과 부서 이름을 출력(부서 이름을 스칼라 서브쿼리로)
정답 :
SELECT EMPNO, ENAME,
(SELECT DNAME
FROM DEPT D
WHERE D.DEPTNO = E.DEPTNO) AS DNAME
FROM EMP E
WHERE DEPTNO = 10;
예제) EMP의 각 직원의 사번, 이름, 부서번호, 급여와 함께 급여 총 합을 출력(총 합을 스칼라 서브쿼리로)
정답 :
SELECT EMPNO, ENAME, DEPTNO, SAL,
(SELECT SUM(SAL)
FROM EMP) AS SUM_SAL
FROM EMP;
예제) 서브쿼리와 아우터 조인
SELECT E1.ENAME AS 사원명,
(SELECT E2.ENAME
FROM EMP E2
WHERE E1.MGR = E2.EMPNO) AS 상위관리자명
FROM EMP E1;
☞ KING의 경우 MGR 컬럼 값이 NULL이므로 MGR = EMPNO에 만족하는 E2.ENAME 값이 없지만, 스칼라 서브쿼리는 무조건 메인쿼리절이 출력하는 대상에 대해 항상 값을 리턴해야 하므로 생략되지 않고 NULL로 출력됌
10. 집합 연산자
● 집합 연산자
- SELECT문 결과를 하나의 집합으로 간주, 그 집합에 대한 합집합, 교집합, 차집합 연산
- SELECT문과 SELECT문 사이에 집합 연산자 정의
- 두 집합의 컬럼이 동일하게 구성되어야 함(각 컬럼의 데이터 타입과 순서 일치 필요)
- 전체 집합의 데이터 타입과 컬럼명은 첫번째 집합에 의해 결정됌
● 합집합
- 두 집합의 총 합 출력
- UNION과 UNION ALL 사용 가능
- UNION
- 중복된 데이터는 한 번만 출력
- 중복된 데이터를 제거하기 위해 내부적으로 정렬 수행
- 중복된 데이터가 없을 경우 UNION사용 대신 UNION ALL 사용(불필요한 정렬이 발생할 수 있기 때문)
- UNION ALL
- 중복된 데이터도 전체 출력
예제) 10번 부서 소속이 아닌 직원 정보와 20번 소속 직원 정보가 각각 분리되어있다 가정할 때 두 집합의 합집합
UNION 결과
SELECT EMPNO, ENAME, DEPTNO
FROM EMP
WHERE DEPTNO != 10
UNION
SELECT EMPNO, ENAME, DEPTNO
FROM EMP
WHERE DEPTNO = 20;
UNION ALL 결과
SELECT EMPNO, ENAME, DEPTNO
FROM EMP
WHERE DEPTNO != 10
UNION ALL
SELECT EMPNO, ENAME, DEPTNO
FROM EMP
WHERE DEPTNO = 20;
● 교집합
- 두 집합 사이에 INTERSECT
- 두 집합의 교집합(공통으로 있는 행)출력
예제) 10번 부서 정보와 20번 부서 정보가 각각 분리되어있다 가정할 때 두 집합의 교집합
정답 :
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP
WHERE DEPTNO != 10
INTERSECT
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP
WHERE DEPTNO != 20;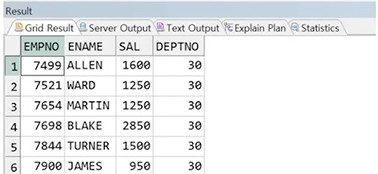
☞ 부서번호가 10번이 아닌 집합은 20, 30번이고, 20번이 아닌 부서원은 10, 30번 부서원이므로 두 집합의 교집합인 30번 부서원 정보만 출력됌
● 차집합
- 두 집합 사이에 MINUS 전달
- 두 집합의 차집합(한 쪽 집합에만 존재하는 행) 출력
- A-B와 B-A는 다르므로 집합의 순서 주의!
예제) 10번이 아닌 부서 정보와 20번 부서 정보가 각각 분리되어있다 가정할 때 두 집합의 차집합
정답 :
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP
WHERE DEPTNO != 10
MINUS
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP
WHERE DEPTNO = 20;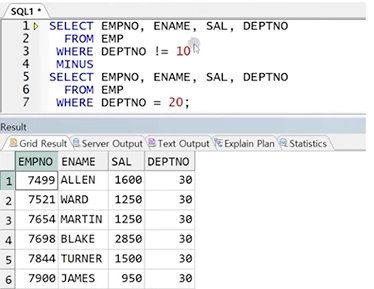
☞ 부서번호가 10번이 아닌 (20, 30)번인 집합에서 20번 집합을 빼면 30번 부서원 집합만 출력
● 집합 연산자 사용 시 주의사항
- 두 집합의 컬럼 수 일치
- 두 집합의 컬럼 순서 일치
- 두 집합의 각 컬럼의 데이터 타입 일치
- 각 컬럼의 사이즈는 달라도 됨
- 개별 SELECT문에 ORDER BY 전달 불가(GROUP BY 전달 가능)
예제) 두 집합의 컬럼의 데이터타입이 다른 경우 에러 발생, 아래와 같은 EMP_T1 테이블이 있다고 가정, EMP와의 합집합 출력
정답 :
DESC EMP;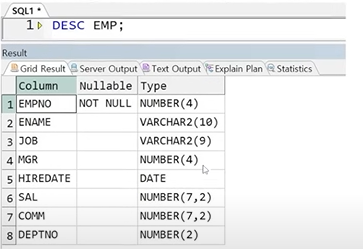
DESC EMP_T1;
** 에러)
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP
WHERE DEPTNO = 10
UNION
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP_T1;
☞ EMPNO 컬럼 데이터 타입이 서로 다름
** 해결)
SELECT EMPNO, ENAME, SAL, DEPTNO
FROM EMP
WHERE DEPTNO = 10
UNION
SELECT TO_NUMBER(EMPNO), ENAME, SAL, DEPTNO
FROM EMP_T1;
11. 그룹 함수
● 그룹 함수
- 숫자 함수 중 여러 값을 전달하여 하나의 요약값을 출력하는 다중 행 함수
- 수학 / 통계 함수들(기술 통계 함수)
- GROUP BY절에 의해 그룹 별 연산 결과를 리턴함
- 반드시 한 컬럼만 전달
- NULL은 무시하고 전달
● COUNT
- 행의 수를 세는 함수
- 대상 컬럼은 * 또는 단 하나의 컬럼만 전달 가능(* 사용 시 모든 컬럼의 값이 널일 때만 COUNT 제외)
- 문자, 숫자, 날짜 컬럼 모두 전달 가능
- 행의 수를 세는 경우 NOT NULL 컬럼을 찾아 세는 것이 좋음(PK 컬럼)
** 문법
COUNT(대상)
예제) 각 컬럼의 COUNT 결과
정답 :
SELECT COUNT(*),
COUNT(EMPNO),
COUNT(COMM)
FROM EMP;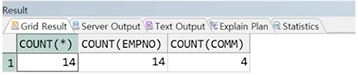
☞ NULL을 포함한 컬럼은 전체 행의 수와 다르게 출력됨
● SUM
- 총 합 출력
- 숫자 컬럼만 전달 가능
예제) 급여의 전체 총 합
정답 :
SELECT SUM(SAL)
FROM EMP;
● AVG
- 평균 출력
- 숫자 컬럼만 전달 가능
- NULL을 제외한 대상의 평균을 리턴하므로 전체 대상의 평균 연산 시 주의
** 문법
AVG(대상)
예제) 평균 계산 결과
정답 :
SELECT AVG(COMM),
SUM(COMM) / COUNT(EMPNO) AS ABG2
AVG(NVL(COMM, 0)) AS AVG3
FROM EMP;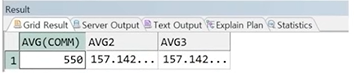
☞ AVG를 사용하면 NULL을 제외한 나머지에 대한 평균(4명에 대한) 리턴, 공식에 의해 직접 계산한 평균은 14명에 대한 평균
☞ NVL 함수를 사용하여 NULL을 0으로 치환 후 평균을 구하면 총 14명에 대한 평균과 같아짐
● MIN / MAX
- 최대, 최소 출력
- 날짜, 숫자, 문자 모두 가능(오름차순 순서대로 최소, 최대 출력)
** 문법
MIN / MAX (대상)
예제) 각 컬럼의 최대, 최소
정답 :
SELECT MIN(ENAME), MAX(ENAME),
MIN(SAL), MAX(SAL)
MIN(HIREDATE), MAX(HIREDATE)
FROM EMP;
● VARIANCE / STDDEV
- 분산과 표준편차
- 표준편차는 분산의 루트값
※ 분산 : 변량들이 퍼져있는 정도, 분산이 크면 들쭉날쭉 불안정하다는 의미
표준편차 : 분산은 수치가 너무 커서 제곱근으로 적달하게 줄인 값
** 문법
VARIANCE / STDDEV(대상)
예제) 분산과 표준편차
정답 :
SELECT VARIANCE(SAL),
STDDEV(SAL)
FROM EMP;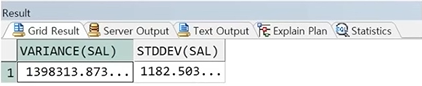
● GROUP BY FUNCTION
- GROUP BY절에 사용하는 함수
- 여러 GROUP BY 결과를 동시에 출력(합집합)하는 기능
- 그룹핑 할 그룹을 정의(전체 소계 등)
예제) 본 GROUP BY 기능 : 그룹 별 연산값만 출력되므로 전체 소계와 함께 출력될 수 없음
SELECT DEPTNO, SUM(SAL)
FROM EMP
GROUP BY DEPTNO;
1. GROUPING SETS(A, B, ...)
- A별, B별 그룹 연산 결과 출력
- 나열 순서는 중요하지 않음
- 기본 출력 전체 총 계는 출력되지 않음
- NULL 혹은 ()를 사용하여 전체 총 합 출력 가능
예제) DEPTNO 별 SAL의 총 합 결과와 JOB 별 SAL으 총 합 결과의 합집합
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY GROUPING SETS(DEPTNO, JOB);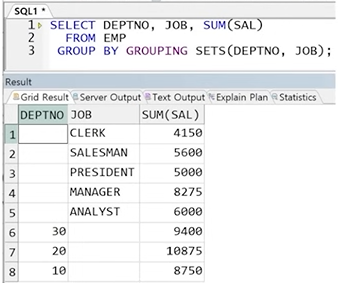
☞ GROUPING SETS에 나열한 대상에 대해 각 GROUP BY의 결과를 출력해 줌
** UNION ALL로 대체 가능
SELECT DEPTNO, NULL AS JOB, SUM(SAL)
FROM EMP
GROUP BY DEPTNO
UNION ALL
SELECT NULL, JOB, SUM(SAL)
FROM EMP
GROUP BY JOB;
예제) 부서 별 급여 총 합과 업무별 급여 총 합, 그리고 전체 급여의 합을 출력
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY GROUPING SETS(DEPTNO, JOB, ());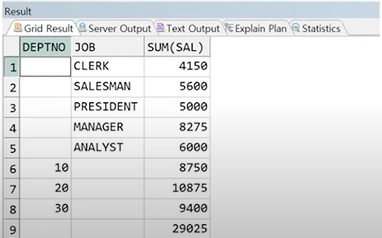
2. ROLLUP(A, B)
- A별, (A, B)별, 전체 그룹 연산 결과 출력
- 나열 대상의 순서가 중요함
- 기본적으로 전체 총 계가 출력됨
예제) ROLLUP(DEPTNO, JOB) -> DEPTNO별, (DEPTNO, JOB)별, 전체 연산 결과 출력
정답 :
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB);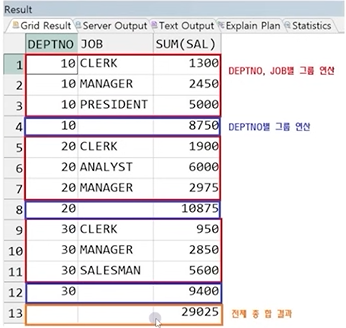
** UNION ALL로 대체 가능
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY DEPTNO, JOB
UNION ALL
SELECT DEPTNO, NULL, SUM(SAL)
FROM EMP
GROUP BY DEPTNO
UNION ALL
SELECT NULL, NULL, SUM(SAL)
FROM EMP;
12. 윈도우 함수
● WINDOW FUNCTION
- 서로 다른 행의비교나 연산을 위해 만든 함수
- GROUP BY를 쓰지 않고 그룹 연산 가능
- LAG, LEAD, SUM, AVG, MIN, MAX, COUNT, RANK
** 문법
SELECT 윈도우함수([대상]) OVER([PARTITION BY 컬럼]
[ORDER BY 컬럼 ASC | DESC]
[ROWS | RANGE BETWEEN A AND B]);
** PARTITION BY 절 : 출력할 총 데이터 수 변화 없이 그룹 연산 수행할 GROUP BY 컬럼
** ORDER BY 절
- RANK의 경우 필수(정렬 컬럼 및 정렬 순서에 따라 순위 변환)
- SUM, AVG, MIN, MAX, COUNT 등은 누적 값 출력 시 사용
** ROWS | RANGE BETWEEN A AND B
- 연산 범위 설정
- ORDER BY절 필수
※ PARTITION BY, ORDER BY, ROWS .. 전달 순서 중요(ORDER BY를 PARTITION BY 전에 사용 불가)
예제) 그룹 함수 오류(윈도우 함수가 필요한 이유)
SELECT EMPNO, ENAME, SAL, DEPTNO, SUM(SAL)
FROM EMP;
☞ 전체를 출력하는 컬럼과 그룹함수 결과는 함께 출력할 수 없음
● 그룹 함수의 형태
- SUM, COUNT, AVG, MIN, MAX 등
- OVER절을 사용하여 윈도우 함수로 사용 가능
- 반드시 연산할 대상을 그룹 함수의 입력값으로 전달
SELECT SUM(대상) OVER([PARTITION BY 컬럼]
[ORDER BY 컬럼 ASC | DESC]
[ROWS | RANGE BETWEEN A AND B]);
1) SUM OVER()
- 전체 총 합, 그룹 별 총 합 출력 가능
예시) 각 직원 정보화 함께 급여 총 합 출력
정답 :
1. 서브쿼리 사용
SELECT EMPNO, ENAME, SAL, DEPTNO,
(SELECT SUM(SAL) FROM EMP) AS TOTAL
FROM EMP;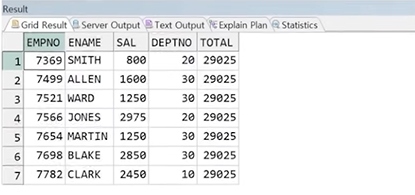
2. 윈도우 함수 사용
SELECT EMPNO, ENAME, SAL, DEPTNO,
SUM(SAL) OVER() AS TOTAL
FROM EMP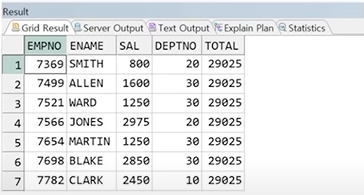
2. AVG OVER() : SUM과 동일하게 사용
예제) 각 직원 정보와 해당 직원이 속한 부서의 평균 급여 출력
SELECT EMPNO, ENAME, SAL, DEPTNO,
AVG(SAL) OVER(PARTITION BY DEPTNO) AS AVG_SAL
FROM EMP;
3. MIN / MAX OVER() : SUM과 동일하게 사용
예제) 각 직원 정보와 해당 직원이 속한 부서의 최대급여를 함께 출력
SELECT EMPNO, ENAME, SAL, DEPTNO
MAX(SAL) OVER(PARTITION BY DEPTNO) AS 부서별급여총합
FROM EMP;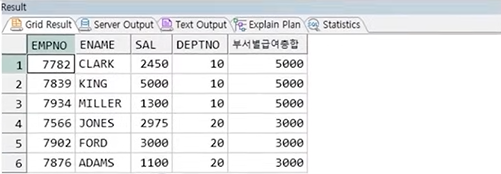
4. COUNT : SUM과 동일하게 사용
** 윈도우 함수의 연산 범위: 집계 연산 시 행의 범위 설정 가능
- ROWS, RANGE 차이
- ) ROWS : 값이 같더라도 각 행씩 연산
- ) RANGE : 같은 값의 경우 하나의 RANGE로 묶어서 동시 연산(DEFAULT)
- BETWEEN A AND B
- A) 시작점 정의
- CURRENT ROW : 현재 행 부터
- UNBOUNDED PRECEDING : 처음부터(DEFAULT)
- N PRECEDING : N 이전부터
- B) 마지막 시점 정의
- CURRENT ROW : 현재 행 까지(DEFAULT)
- UNBOUNDED FOLLOWING : 마지막까지
- N FOLLOWING : N 이후까지
- A) 시작점 정의
예제) RANGE_TEST 테이블에서의 범위 설정에 따른 누적합
1. RANGE 범위 전달(DEFAULT) : 값이 같을 경우 같은 범위로 취급하여 동시 연산
SELECT R.*,
SUM(SAL) OVER(ORDER BY SAL)
FROM RANGE_TEST R;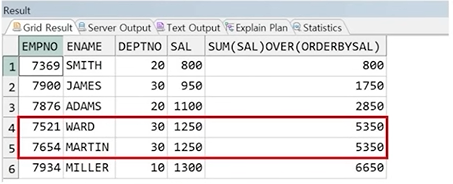
2. ROWS 범위 설정 시 : 각 행 별로 연산 수행
SELECT R.*,
SUM(SAL) OVER(ORDER BY SAL
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS RESULT1
FROM RANGE_TEST R;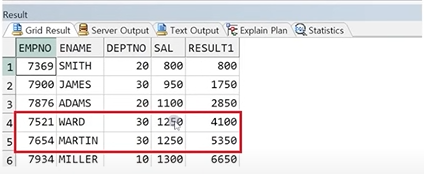
3. BETWEEN A AND B 수정 시
SELECT R.*,
SUM(SAL) OVER(ORDER BY SAL
ROWS BETWEEN UNBOUNDED PRECEDING
AND 1 FOLLOWING) AS RESULT2
FROM RANGE_TEST R;
☞ UNBOUNDED PRECEDING AND 1 FOLLOWING : 각 행마다 누적 합 계산 시 처음부터 다음행까지 계산
● 순위 관련 함수
- RANK(순위)
- 1) RANK WITHIN GROUP
- 특정값에 대한 순위 확인(RANK WITHNIN)
- 윈도우 함수가 아닌 일반 함수
- 1) RANK WITHIN GROUP
** 문법
SELECT RANK(값) WITHIN GROUP(ORDER BY 컬럼);
예시) EMP에서 급여가 3000이면 전체 급여 순위가 얼마?
정답 :
SELECT RANK(3000) WITHIN GROUP(ORDER BY SAL DESC) AS RANK_VALUE
FROM EMP;
2.2) RANK() OVER()
- 전체 중 / 특정 그룹 중 값의 순위 확인
- ORDER BY절 필수
- 순위를 구할 대상을 ORDER BY절에 명시(여러 개 나열 가능)
- 그룹 내 순위를 구할 시 PARTITION BY 절 사용
** 문법
SELECT RANK() OVER([PARTITION BY 컬럼]
ORDER BY 컬럼 ASC | DESC);
예시) 각 직원의 급여의 전체 순위(큰 순서대로)
SELECT ENAME, DEPTNO, SAL,
RANK() OVER(ORDER BY SAL DESC) AS RANK_VALUE1
FROM EMP;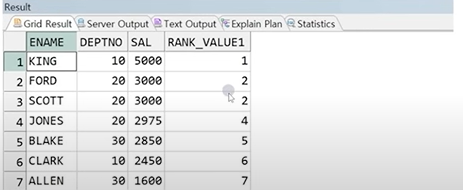
예시) 각 직업 이름, 부서번호, 급여, 부서 별 급여 순위(큰 순서대로)
SELECT ENAME, DEPTNO, SAL,
RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS RANK1
FROM EMP;
3. DENSE_RANK
- 누적 순위
- 값이 같을 때 동일한 순위 부여 후 다음 순위가 바로 이어지는 순위 부여 방식
ex) 1등이 5명이더라도 그 다음 순위가 2등
4. ROW_NUMBER
- 연속된 행 번호
- 동일한 순위를 인정하지 않고 단순히 순서대로 나열한대로의 순서 값 리턴
예제) RANK, DENSE_RANK, ROW_NUMBER 비교
SELECT ENAME, DEPTNO, SAL,
RANK() OVER(ORDER BY SAL DESC) AS RANK_VALUE1,
DENSE_RANK() OVER(ORDER BY SAL DESC) AS RANK_VALUE2,
ROW_NUMBER() OVER(ORDER BY SAL DESC) AS RANK_VALUE3
FROM EMP;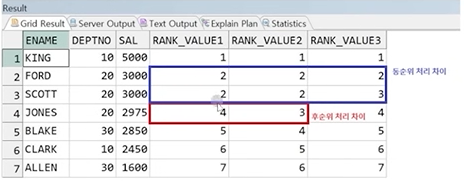
● LAG, LEAD
- 행 순서대로 각각 이전 값(LAG), 이후 값(LEAD) 가져오기
- ORDER BY 절 필수
** 문법
SELECT LAG(컬럼,
[N])
OVER ([PARTITION BY 컬럼]
ORDER BY 컬럼 [ASC | DESC]);
예시) EMP에서 바로 이전 입사자와 급여 비교
SELECT ENAME, HIREDATE, SAL,
LAG(SAL) OVER(ORDER BY HIREDATE) AS 바로직전상사급여
FROM EMP;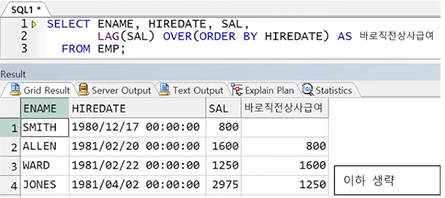
참고) 이전 / 이후 값 가져올 때 이전 값이 같더라도 항상 행의 순서대로 이전, 이후 하나를 가져옴
따라서 사용자가 이전 / 이후 값을 가져올 원하는 행 배치를 ORDER BY를 통해 충분히 전달한 후 이전 / 이후 값을 가져와야 함
SELECT EMP.*
LAG(SAL) OVER(ORDER BY DEPTNO, SAL) AS RESULT
FROM EMP;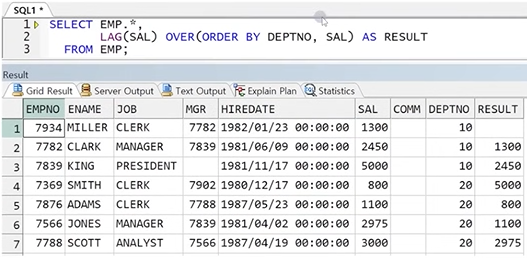
● FIRST_VALUE, LAST_VALUE
- 정렬 순서대로 정해진 범위에서의 처음 값, 마지막 값 출력
- 순서와 범위 정의에 따라 최솟값과 최댓값 리턴 가능
- PARTITINO BY, ORDER BY 절 생략 가능
** 문법
SELECT FIRST_VAULE(대상) OVER([PARTITION BY 컬럼]
[ORDER BY 컬럼]
[RNAGE | ROWS BETWEEN A AND B])
예제) FIRST_VALUE를 사용한 최소, 최대 출력
SELECT ENAME, DEPTNO, SAL,
FIRST_VALUE(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL) AS MIN_VALUE,
FIRSE_VALUE(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS MAX_VALUE
FROM EMP;
예제) LAST_VALUE를 사용한 최소, 최대 출력
SELECT ENAME, DEPTNO, SAL,
LAST_VALUE(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL) AS VALUE1,
LAST_VALUE(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS MAX_VALUE,
LAST_VALUE(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL DESC
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS MIN_VALUE
FROM EMP
WHERE DEPTNO IN (10, 20);
● NTILE
- 행을 특정 컬럼 순서에 따라 정해진 수의 그룹으로 나누기 위한 함수
- 그룹 번호가 리턴됨
- ORDER BY 필수
- PARTITION BY를 사용하여 특정 그룹을 또 원하는 수 만큼 그룹 분리 가능
- 총 행의 수가 명확히 나눠지지 않을 때 앞 그룹의 크기가 더 크게 분리됨
ex) 14명 3개 그룹 분리 시 -> 5, 5, 4로 나뉨
** 문법
SELECT NTILE(N) OVER([PARTITION BY 컬럼]
ORDER BY 컬럼 ASC | DESC)
예제) NTILE을 사용한 그룹 분리
SELECT ENAME, SAL, DEPTNO,
NTILE(2) OVER (ORDER BY SAL) AS GROUP_NUMBER
FROM EMP;
● 비율관련 함수
- RATIO_TO_REPORT
- 각 값의 비율 리턴(전체 비율 또는 특정 그룹 내 비율 가능)
- ORDER BY 사용 불가
** 문법
RATIO_TO_REPORT(대상) OVER([PARTITION BY 컬럼])
2. CUME_DIST : 각 행의 수에 대한 누적비율
- 특정 값이 전체 데이터 집합에서 차지하는 위치를 백분위수로 계산하여 출력
- ORDER BY를 사용하여 누적 비율을 구하는 순서를 정할 수 있음
- ORDER BY 필수
- 값이 3개면 1/3 = 0.33부터 시작
** 문법
CUME_DIST() OVER([PARTITION BY 컬럼]
ORDER BY 컬럼 ASC | DESC)
3. PERCENT_RANK
- PERCENTILE(분위수) 출력
- 전체 COUNT 중 상대적 위치 출력( 0 ~ 1 범위 내)
- ORDER BY 필수
** 문법
PERCENT_RANK() OVER([PARTITION BY 컬럼]
ORDER BY 컬럼 ASC | DESC)
예제) CUME_DIST와 PERCENT_RANK 비교
SELECT CUME_DIST() OVER(ORDER BY SAL) AS CUME_DIST
PERCENT_RANK() OVER(ORDER BY SAL) AS PERCENT_RANK, SAL
FROM EMP
WHERE DEPTNO = 10;
예제) 누적 비율 비교
SELECT ENAME, DEPTNO, SAL,
ROUND(RATIO_TO_REPORT(SAL) OVER(PARTITION BY DEPTNO), 2) AS RATE1,
ROUND(CUME_DIST() OVER(PARTITION BY DEPTNO
ORDER BY SAL), 2) AS RATE2,
ROUND(CUME_DIST() OVER(PARTITION BY DEPTNO
ORDER BY SAL, ENAME), 2) AS RATE3
FROM EMP;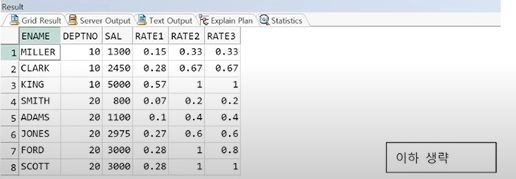
예제) PERCENT_RANK 예제
SELECT ENAME, DEPTNO, SAL,
PERCENT_RANK() OVER(ORDER BY SAL) AS TOTAL_PERCENTILE
FROM EMP;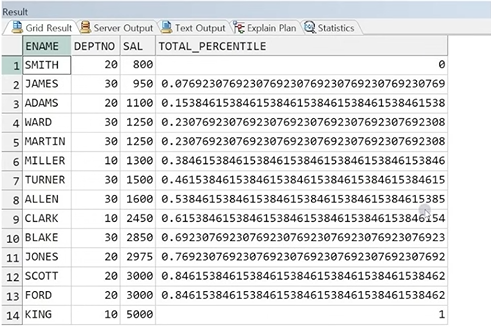
13. TOP N QUERY
● TOP N QUERY
- 페이징 처리를 효과적으로 수행하기 위해 사용
- 전체 결과에서 특정 N개 추출
ex) 성적 상위자 3명
● TOP-N 행 추출 방법
- ROWNUM
- RANK
- FETCH
- TOP N(SQL Server)
● ROWNUM
- 출력된 데이터 기준으로 행 번호 부여
- 절대적인 행 번호가 아닌 가상의 번호이므로 특정 행을 지정할 수 없음( = 연산 불가)
- 첫번째 행이 증가한 이후 할당되므로 '>' 연산 사용 불가(0은 가능)
예제) ROWNUM 출력 형태
SELECT ROWNUM, EMP.*
FROM EMP
WHERE SAL >= 1500;
예제) ROWNUM 잘못된 사용
1. '>' 조건 전달 불가
SELECT * FROM EMP
WHERE ROWNUM > 1;예제) ROWNUM 올바른 사용
SELECT EMPNO, ENAME, DEPTNO, SAL
FROM EMP
WHERE ROWNUM <= 5;
☞ EQUAL 비교 시 작다(<)와 함꼐 사용하면 1부터 순서대로 뽑을 수 있기 때문에 출력 가능함
정렬 순서에 따라 출력되는 ROWNUM이 달라짐
예제) EMP 테이블에서 급여가 높은 순서대로 4~6번째 해당하는 직원 정보 출력
** 잘못된 예
SELECT *
FROM (SELECT * FROM EMP ORDER BY SAL DESC)
WHERE ROWNUM BETWEEN 4 AND 6
ORDER BY SAL DESC;
☞ ROWNUM 시작값(1)이 정의되지 않았으므로 1을 건너띄고 그 다음 행번호에 대한 추출 불가
** 해결1 : 인라인 뷰에서 각 행마다 순위를 직접 부여
SELECT *
FROM (SELECT ROWNUM AS RN, A.*
FROM (SELECT *
FROM EMP
ORDER BY SAL DESC) A) B
WHERE RN BETWEEN 4 AND 6
ORDER BY SAL DESC;
☞ 서브쿼리를 통해 얻은 결과에 ROWNUM을 다시 부여하고 새로운 테이블인 것 처럼 사용(인라인 뷰)
** 해결2 : 윈도우 함수의 RANK 사용
SELECT *
FROM (SELECT EMP.*
RANK() OVER(ORDER BY SAL DESC) AS RN
FROM EMP) A
WHERE RN BETWEEN 4 AND 6
ORDER BY SAL DESC;
● FETCH
- 출력될 행의 수를 제한하는 절
- ORACLE 12C 이상부터 제공(이전 버전에는 ROWNUM 주로 사용)
- SQL Server 사용 가능
- ORDER BY 절 뒤에 사용(내부 파싱 순서도 ORDER BY 뒤)
** 문법
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
OFFSET N { ROW | ROWS}
FETCH { FIRST | NEXT } N { ROW | ROWS } ONLY
- OFFSET : 건너뛸 행의 수
ex) 성적 높은 순 1등 제외, 나머지 3명 - N : 출력할 행의 수
- FETCH : 출력할 행의 수를 전달하는 구문
- FIRST : OFFSET을 쓰지 않았을 때 처음부터 N행 출력 명령
- NEXT : OFFSET을 사용했을 경우 제외한 행 다음부터 N행 출력 명령
- ROW | ROWS : 행의 수에 따라 하나일 경우 단수, 여러값이면 복수형(특별히 구분하지 않아도 됨)
예시) EMP에서 SAL 순서대로 상위 5명(19C에서 실행)
SELECT EMPNO, ENAME, JOB, SAL
FROM EMP
ORDER BY SAL DESC FETCH FIRST 5 ROWS ONLY;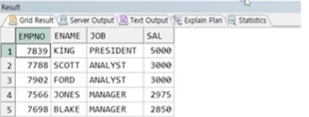
예제) EMP 테이블에서 급여가 높은 순서대로 4~6번째 해당하는 직원 정보 출력
SELECT EMPNO, ENAME, JOB, SAL
FROM EMP
ORDER BY SAL DESC
OFFSET 3 ROW
FETCH FIRST 2ROW ONLY;
● TOP N 쿼리
- SQL SERVER에서의 상위 n개 행 추출 문법
- 서브쿼리 사용 없이 하나의 쿼리로 정렬된 순서대로 상위 n개 추출 가능
- WITH TIES를 사용하여 동순위까지 함께 출력 가능
** 문법
SELECT TOP N 컬럼1, 컬럼2, ...
FROM 테이블명
ORDER BY 정렬컬럼명 [ASC | DESC] ...
예제) EMP테이블의 상위 급여자 2명 출력(SQL Server에서 수행)
1.
SELECT TOP 2 ENAME, SAL
FROM EMP
ORDER BY SAL DESC;
2.
SELECT TOP 2 WITH TIES ENAME, SAL
FROM EMP
ORDER BY SAL DESC;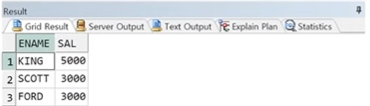
☞ SAL은 큰 순서대로 5000, 3000, 3000이라 3000이 공동 2위이지만, TOP 2는 2개만 출력, WITH TIES를 사용하면 동순위 행도 함께 출력 가능
14. 계층형 질의
● 계층형 질의
- 하나의 테이블 내 각 행끼리 관계를 가질 때, 연결고리를 통해 행과 행 사이의 계층(depth)을 표현하는 기법
ex) DEPT2에서의 부서별 상하관계 - PRIOR의 위치에 따라 연결하는 데이터가 달라짐
** 문법
SELECT 컬럼명
FROM 테이블명
START WITH 시작조건 -- 시작점을 지정하는 조건 전달
CONNECT BY [NOCYCLE] PRIOR 연결조건; -- 시작점 기준으로 연결 데이터를 찾아가는 조건
** START WITH : 데이터를 출력할 시작 지정하는 조건
** CONNECT BY PRIOR : 행을 이어나갈 조건
** NOCYCLE : 순환이 발생하면 무한 루프가 될 수 있기 때문에 이를 방지하고자 사용
예제) DEPT2 테이블에 대해 각 부서의 레벨을 출력(최상위 부서가 1레벨)
SELECT D.*, LEVEL
FROM DEPT2 D
START WITH PDEPT IS NULL
CONNECT BY PRIOR DCODE = PDEPT;
예제) 계층형 질의 조건 전달
1. CONNECT BY 절에 전달 : 연결 조건이 추가되었으므로 모든 조건이 만족할 경우만 하위 레벨로 연결
SELECT D.*
FROM DEPT2 D
START WITH PDEPT IS NULL
CONNECT BY PRIOR DCODE = PEDPT AND AREA = '서울지사';
2. WHERE절에 전달 : 모든 출력 결과 중 '서울지사' 데이터만 출력됨
SELECT D.*, LEVEL
FROM DEPT2 D
WHERE AREA = '서울지사'
START WITH PDEPT IS NULL
CONNECT BY PRIOR DCODE = PDEPT;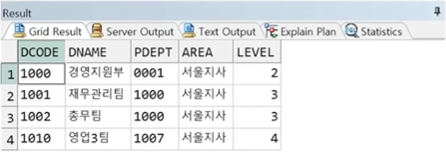
※ 계층형 질의 가상 컬럼
- LEVEL : 각 DEPTH를 표현(시작점부터 1)
- CONNECT_BY_ISLEAF : LEAF NODE(최하위 노드) 여부 (참 : 1, 거짓 : 0)
※ 계층형 질의 가상 함수
- CONNECT_BY_ROOT 컬럼명 : 루트 노드의 해당하는 컬럼값
- SYS_CONNECT_BY_PATH(컬럼, 구분자) : 이어지는 경로 출력
- ORDER SIBLINGS BY 컬럼 : 같은 LEVEL일 경우 정렬 수행
- CONNECT_BY_ISCYCLE : 계층형 쿼리의 결과에서 순환이 발생했는지 여부
예제) 계층형 질의절 가상 컬럼 및 함수의 사용
SELECT D.*, LEVEL,
CONNECT_BY_ROOT DNAME,
SYS_CONNECT_BY_PATH(DNAME, '-')
FROM DEPARTMENT D
START WITH DEPTNO = 10
CONNECT BY PRIOR DEPTNO = PDEPT
ORDER SIBLINGS BY DNAME;
☞ ORDER SIBLINGS BY를 사용하여 같은 레벨일 경우 DNAME 오름차순으로 정렬,
2레벨은 자연과학부 < 컴퓨터공학부 순서대로 출력되며, 자연과학부 내 3레벨은 수학과 < 통계학과 < 화학공학과 순서대로 리턴
예제) NOCYCLE 옵션
< EMPLOYEE DATA >

< NOCYCLE 옵션 없이 - ERROR 발생>
SELECT EMPLOYEE_ID, NAME, LEVEL
FROM EMPLOYEE2
START WITH EMPLOYEE_ID = 1000
CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID;
☞ 1000번 직원의 매니저는 2000사원인데, 2000번 사원도 1000번 직원이 매니저이므로 서로 순환구조를 가짐
이런 관계에서 NOCYCLE 없이는 에러가 발생함
< NOCYCLE 옵션 수행 시 - 정상 출력 >
SELECT EMPLOYEE_ID, NAME, LEVEL,
CONNECT_BY_ISCYCLE AS IS_CYCLE
FROM EMPLOYEE2
START WITH EMPLOYEE_ID = 1000
CONNECT BY NOCYCLE PRIOR EMPLOYEE_ID = MANAGER_ID;
15. PIVOT과 UNPIVOT (데이터의 구조를 변경하는 기능)
● 데이터의 구조
1. LONG DATA(Tidy data)
- 하나의 속성이 하나의 컬럼으로 정의되어 값들이 여러 행으로 쌓이는 구조
- RDBMS의 테이블 설계 방식
- 다른 테이블과의 조인 연산이 가능한 구조
** LONG DATA

2. WIDE DATA(Cross table)
- 행과 컬럼에 유의미한 정보 전달을 목적으로 작성하는 교차표
- 하나의 속성값이 여러 컬럼으로 분리되어 표현
- RDBMS에서 WIDE 형식으로 테이블 설계 시 값이 추가될 때 마다 컬럼이 추가되야 하므로 비효율적
- 다른 테이블과 조인 연산이 불가능
- 주로 데이터를 요약할 목적으로 사용
** WIDE DATA
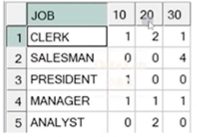
☞ 컬럼의 정보는 부서번호로, 하나의 관찰대상(속성)을 한 컬럼으로 정의하지 않고 값의 종류별로 컬럼을 분리하였음
● 데이터 구조 변경
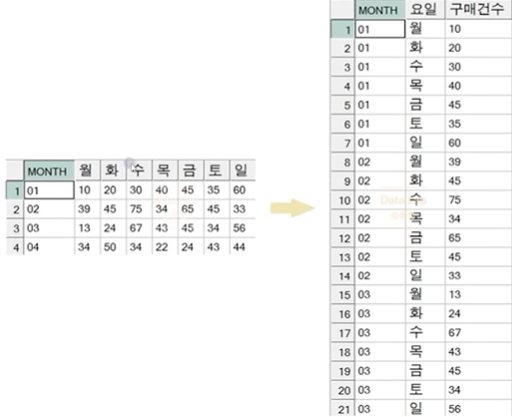
1. PIVOT : LONG -> WIDE
2. UNPIVOT : WIDE -> LONG
● PIVOT
- 교차표를 만드는 기능
- STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼의 정의가 중요!
- FROM 절에 STACK, UNSTACK, VALUE 컬럼명만 정의 필요(필요 시 서브쿼리 사용하여 필요 컬럼 제한)
- PIVOT 절에 UNSTACK, VALUE 컬럼명 정의
- PIVOT 절 IN 연산자에 UNSTACK 컬럼 값을 정의
- FROM 절에 선언된 컬럼 중 PIVOT절에서 선언한 VALUE 컬럼, UNSTACK 컬럼을 제외한 모든 컬럼은 STACK 컬럼이 됨

** 문법
SELECT *
FROM 테이블명 또는 서브쿼리
PIVOT (VALUE컬렴명 FROM UNSTACK컬럼명 IN (값1, 값2, 값3));
※ 반드시 FROM 절에 STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼 모두 명시!
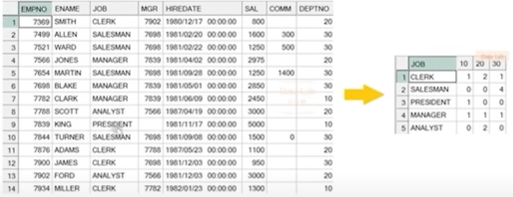
예제) EMP 테이블에서 아래와 같이 JOB 별 DEPTNO 별 도수(COUNT) 출력
SELECT *
FROM (SELECT EMPNO, JOB, DEPTNO FROM EMP)
PIVOT (COUNT(EMPNO) FOR DEPTNO IN (10, 20, 30));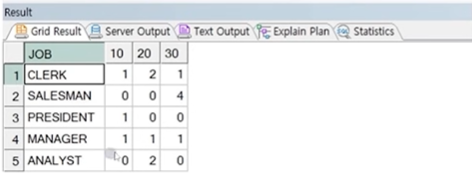
※ 주의 : 이 때 FROM 절 서브쿼리 안에 JOB이 없으면 아래와 같이 그냥 부서별로의 도수가 출력됨
SELECT *
FROM (SELECT EMPNO, DEPTNO FROM EMP)
PIVOT (COUNT(EMPNO) FOR DEPTNO IN (10, 20, 30));
※ 주의 : 이 때 FROM에 서브쿼리로 컬럼을 제한하지 않으면 STACK 컬럼이 많아짐
SELECT *
FROM EMP
PIVOT (COUNT(EMPNO) FOR DEPTNO IN (10, 20, 30));
☞ FROM절에 서브쿼리로 필요한 컬럼만 정의하지 않으면 EMP 테이블의 모든 컬럼 중 PIVOT 절에 선언된 EMPNO, DEPTNO 컬럼을 제외한 모든 컬럼이 STACK 처리됨
예제) 다음의 테이블에서 성별 연도 별 구매량 총 합을 표현하는 교차표 작성 (STACK 컬럼 : 성별)

SELECT *
FROM (SELECT 년도, 성별, 구매량 FROM UNSTACK_TEST)
PIVOT (SUM(구매량) FOR 년도 IN (2008, 2009));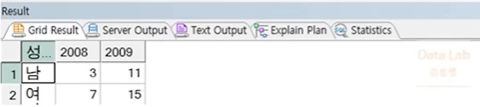
● UNPIVOT
- WIDE 데이터를 LONG 데이터로 변경하는 문법
- STACK 컬럼 : 이미 UNSTACK 되어있는 여러 컬럼을 하나의 컬럼으로 STACK 시 새로 만들 컬럼 이름(사용자 정의)
- VALUE 컬럼 : 교차표에서 셀 자리(VALUE)값을 하나의 컬럼으로 표현하고자 할 때 새로 만들 컬럼명(사용자 정의)
- 값1, 값2, ... : 실제 UNSTACK 되어있는 컬럼 이름들

** 문법
SELECT *
FROM 테이블명 또는 서브쿼리
UNPIVOT (VALUE컬럼명 FOR STACK컬럼명 IN (값1, 값2, ...));
예제) 위 UNSTACK_TEST PIVOT 결과가 STACK_TEST 테이블에 저장되어있을 때, 다시 STACK_TEST 테이블 값을 UNSTACK_TEST 형태로 변경(STACK 처리)
SELECT *
FROM STACK_TEST
UNPIVOT (CNT FOR 년도 IN ("2008", "2009"));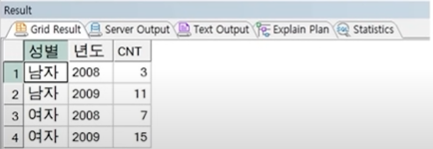
☞ IN 뒤에 값은 UNSTACK 데이터의 컬럼명이 숫자이지만 컬럼명은 숫자이므로 쌍따옴표 전달 필요
16. 정규 표현식
● 정규 표현식
- 문자열의 공통된 규칙을 보다 일반화하여 표현하는 방법
- 정규 표현식 사용 가능한 문자함수 제공(regexp_replace, regexp_substr, regexp_instr, ... )
ex) 숫자를 포함하는, 숫자로 시작하는 4자리, 두번째 자리가 A인 5글자
예제) 일반화 규칙 찾아내기
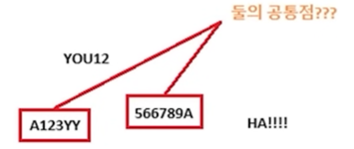
☞ "숫자를 연속적으로 3개 이상 포함하는"이 공통 패턴임
● 정규 표현식 종류
| ₩d | Digit, 0, 1, 2 ... 9 | [ab] | a 또는 b의 한 글자 | ₩n | 그룹번호 |
| ₩D | 숫자가 아닌 것 | [^ab] | a와 b를 제외한 모든 문자 | [:alnum:] | 문자와 숫자 |
| ₩s | 공백 | [0-9] | 숫자 | [:alpha:] | 문자 |
| ₩S | 공백이 아닌 것 | [A-Z] | 대문자 영어 | [:blank:] | 공백 |
| ₩w | 단어 | [a-z] | 소문자 영어 | [:digit:] | Digits |
| ₩W | 단어가 아닌 것 | [A-z] | 모든 영문자 | [:graph:] | Graphical characters [:alnum:], [:punct:] |
| ₩t | Tab | i+ | i가 1회 이상 반복 | [:lower:] | 소문자 |
| ₩n | New Line (엔터 문자) | i* | i가 0회 이상 반복 | [:print:] | 숫자, 문자, 특수문자, 공백 모두 |
| ^ | 시작되는 글자 | i? | 0회에서 1회 반복 | [:punct:] | 특수문자 |
| $ | 마지막 글자 | i{n} | i가 n회 반복 | [:space:] | 공백문자 |
| ₩ | Escape Character (뒤에 기호 의미 제거) |
i{n1, n2} | i가 n1에서 n2회 반복 | [:upper:] | 대문자 |
| | | 또는 | i{n,} | i가 n회 이상 반복 | [:cntrl:] | 제어문자 |
| * | 엔터를 제외한 모든 한 글자 |
() | 그룹지정 | [:xdigit:] | 16진수 |
예제) 전화번호의 일반화

☞ 전화번호는 숫자와 -으로 구성 -> [0~9-]+로 표현 가능([안에 들어가는 패턴이 한자리의 문자열을 구성할 수 있는 값들])
☞ 두 전화번호가 tel값은 동시에 있지만 ")"가 있는 경우와 없는 경우를 표현 -> ?사용(?는 값이 없거나 1개 있음을 의미)
● REGEXP_REPLACE
- 정규식 표현을 사용한 문자열 치환 가능
- (대상, 찾을 문자열, [바꿀 문자열], [검색 위치], [발견 횟수], [옵션])
- 특징
- 바꿀 문자열 생략 시 문자열 삭제
- 검색 위치 생략 시 1
- 발견 횟수 생략 시 0(모든)
- 옵션
- c : 대소를 구분하여 검색
- i : 대소를 구분하지 않고 검색
- m : 패턴을 다중라인으로 선언 가능
예제) ID에서 숫자 삭제
SELECT ID,
REGEXP_REPLACE(ID, '\d', ''),
REGEXP_REPLACE(ID, '[[:digit:]]', '')
FROM PROFESSOR;
☞ 빈 문자열을 전달하여 숫자를 모두 삭제 처리
예제) ID에서 특수 기호 삭제
SELECT ID,
REGEXP_REPLACE(ID, '\w', '') AS RESULT1,
REGEXP_REPLACE(ID, '\W|_', '') AS RESULT2,
REGEXP_REPLACE(ID, '[[:punct:]]', '') AS RESULT3,
FROM PROFESSOR;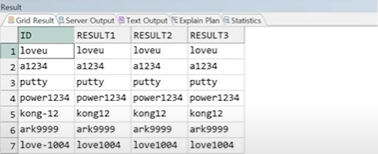
☞ \w는 문자와 숫자, _포함, \W는 \w의 반대 집합이므로 문자와 숫자와 _가 아닌 특수기호와 공백을 의미
예제) PROFESSOR 테이블의 ID에서 문자와 문자 바로 뒤에 오는 숫자를 삭제(대소 구분 X)
SELECT ID,
REGEXP_REPLACE(ID, '[a-z][0-9]') AS 성공1,
REGEXP_REPLACE(ID, '[a-zA-Z][0-9]') AS 성공2,
REGEXP_REPLACE(ID, '[A-z][0-9]') AS 성공3,
REGEXP_REPLACE(ID, '[a-z0-9]') AS 실패1,
REGEXP_REPLACE(ID, '[a-z][0-9]','',1,0,'i') AS 성공4,
FROM PROFESSOR
** kong-12에서 g-12를 지우는 방법
SELECT ID,
REGEXP_REPLACE(ID, '[A-z]-[0-9]') AS 성공1,
REGEXP_REPLACE(ID, '[A-z](-|_)[0-9]') AS 성공2
FROM PROFESSOR;
● REGEXP_SUBSTR
- 정규식 표현식을 사용한 문자열 추출
- 옵션은 REGEXP_SUBSTR과 동일
** 문법
REGEXP_SUBSTR(대상, 패턴, [검색 위치], [발견 횟수], [옵션], [추출 그룹])
** 특징
- 검색위치 생략 시 1
- 발견횟수 생략 시 1
- 추출 그룹은 서브 패턴을 추출 시 그 중 추출할 서브 패턴 번호
예제) 전화번호를 분리하여 지역번호 추출
SELECT TEL,
REGEXP_SUBSTR(TEL, -- 원본
'(\d+)\)(\d+)-(\d+)', -- 패턴(서브패턴과 함께 표현)
1, -- 시작위치
1, -- 발견위치
null, -- 옵션
1) AS 지역번호 -- 추출할 서브패턴(그룹)번호
FROM STUDENT;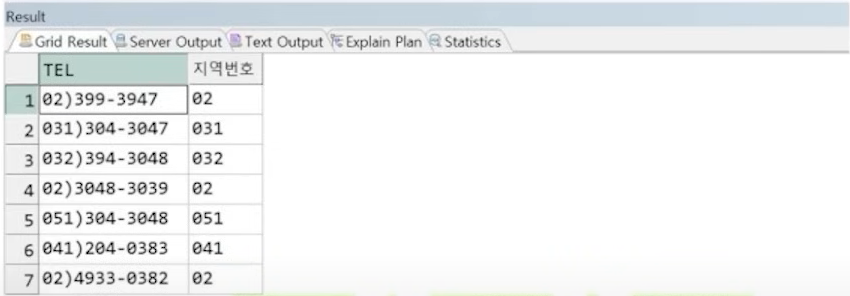
☞ 전화번호 구성 : 숫자 여러개 + ) + 숫자 여러개 + - + 숫자 여러개
차례대로 \d+, \), \d+, -, \d+ 로 표현 가능, 그 중 첫 번째 그룹을 추출
예제) 이메일 아이디 추출(서브패턴 사용)
SELECT EMAIL,
REGEXP_SUBSTR(EMAIL, '(.+)@.+', 1, 1, null, 1) AS EMAIL_ID,
REGEXP_SUBSTR(EMAIL, '((\w | \W)+@[a-z.]+)', 1, 1, null, 1) AS EMAIL_ID
FROM PROFESSOR;
☞ EMAIL 주소는 EMAIL_ID@ENGINE 으로 구성
☞ EMAIL_ID : 몇 특수기호를 제외한 영문, 숫자, 기호로 구성
☞ ENGINE : 영문과 .으로 구성
● REGEXP_INSTR
- 주어진 문자열에서 특정 패턴의 시작 위치를 반환
- 옵션은 REGEXP_SUBSTR과 동일
** 문법
REGEXP_INSTR(원본, 찾을 문자열, [시작 위치], [발견 횟수], [옵션])
** 특징
- 시작위치 생략 시 처음부터 확인(기본값 : 1)
- 발견횟수 생략 시 처음 발견된 문자열 위치 리턴
예제) ID값에서 두번째 발견된 숫자의 위치
SELECT ID,
REGEXP_INSTR(ID, '\d', 1, 2)
FROM PROFESSOR;
☞ \d는 숫자를 나타내는 표현이고, 뒤에 횟수를 지정하지 않으면 한 자리수의 숫자를 의미함
예제) 정규식 표현식을 사용한 패턴에 일치하는 n번쨰 문자열 위치
SELECT REGEXP_INSTR('500 ORACLE PARKWAY, REDWOOD SHORES, CA',
'[^ ]+', 1, 2) AS "REGEXP_INSTR"
FROM DUAL;
☞ 다음과 같은 문자열에서 공백이 아닌 문자열의 반복들 중 처음부터 스캔하여 두 번째 발견된 것의 위치 리턴
● REGEXP_LIKE
- 주어진 문자열에서 특정 패턴을 갖는 경우 반환(WHERE절 사용만 가능)
- 옵션 REGEXP_REPLACE와 동일
** 문법
REGEXP_LIKE(원본, 찾을 문자열, [옵션])
예제) ID값이 숫자로 끝나는 교수 정보 출력
SELECT *
FROM PROFESSOR
WHERE REGEXP_LIKE(ID, '\d$');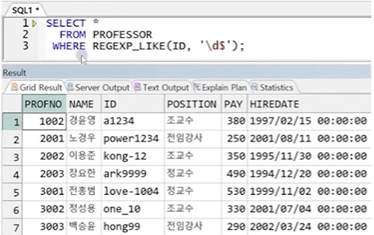
● REGEXP_COUNT
- 주어진 문자열에서 특정 패턴의 횟수를 반환함
- 옵션 REGEXP_REPLACE와 동일
** 문법
REGEXP_COUNT(원본, 찾을 문자열, [옵션])
예제) ID값에서의 숫자의 수
SELECT ID,
REGEXP_COUNT(ID, '\d') AS RESULT1,
REGEXP_COUNT(ID, '\d+') AS RESULT2
FROM PROFESSOR;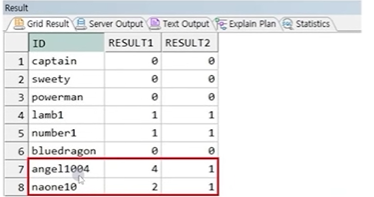
☞ \d는 한 자리수의 숫자를 의미하며 \d+는 연속적인 숫자를 의미. 따라서 COUNT시 연속적인 숫자를 하나로 취습함