SQLD 2과목 정리 PART1. SQL 기본
1. 관계형 데이터베이스 개요
● 데이터베이스(Database)와 DBMS(DataBase Management System)
- 데이터베이스 : 데이터의 집합. 꼭 형식을 갖추지 않아도 엑셀 파일을 모아둔다면 그것 또한 데이터베이스
- DBMS : 데이터를 효과적으로 관리하기 위한 시스템
개인이 파일을 여러 개 묶어서 폴더에 보관하면 데이터를 찾고 관리하는데 많은 비용이 발생
이를 보다 시스템적으로 작동하게 만든 시스템을 DBMS라고 한다.(ORACLE, MYSQL 등)
● 관계형 데이터베이스 구성 요소
- 계정 : 데이터의 접근 제한을 위한 여러 업무별/시스템별 계정이 존재
- 테이블 : DBMS의 DB 안에서 데이터가 저장되는 형식
- 스키마 : 테이블이 어떠한 구성으로 되어있는지, 어떠한 정보를 가지고 있는지에 대한 기본적인 구조를 정의
● 테이블
- 정의
- 엑셀에서의 워크시트처럼 행(low)와 열(column)을 갖는 2차원 구조로 구성
- 데이터를 입력하여 저장하는 최소 단위
- 컬럼은 속성이라고도 부름(모델링 단계마다 부르는 용어가 다름)
- 특징
- 하나의 테이블은 반드시 하나의 유저(계정) 소유여야 함
- 테이블간 관계는 일대일(1:1), 일대다(1:N), 다대다(N:N)의 관계를 가질 수 있음
- 테이블명은 중복될 수 없지만, 소유자가 다른 경우 같은 이름으로 생성 가능
ex) SCOTT 소유의 EMP테이블이 존재, HR 소유의 EMP 테이블 생성 가능(같은 계정 내 동일한 객체 생성 불가) - 테이블은 행 단위로 데이터가 입력, 삭제되며 수정은 값의 단위로 가능
ex) 사원 테이블에 새로운 사원 정보를 사원번호, 사원이름 등의 데이틀 내 모든 컬럼의 값을 동시에 전달하여 입력, 삭제 시에는 해당 사원의 모든 정보가 삭제됨(수정 시에는 특정 직원의 급여만 수정 가능)

※ 객체 : DBMS에서의 객체는 생성하고 변경할 수 있는 하나의 관리 대상
● SQL(Structured Query Language)
- 관계형 데이터베이스에서 데이터 조회 및 조작, DBMS 시스템 관리 기능을 명령하는 언어
- 데이터 정의(DDL), 데이터 조작(DML), 데이터 제어 언어(DCL) 등으로 구분
- SQL 문법은 대,소문자를 구분하지 않음
● 관계형 데이터베이스의 특징
- 데이터의 분류, 정렬, 탐색 속도가 빠름
- 신뢰성이 높고, 데이터의 무결성 보장
- 기존의 작성된 스키마를 수정하기 어려움
- 데이터베이스의 부하를 분석하는 것이 어려움
● 데이터 무결성(integrity)
- 데이터의 정확성과 일관성을 유지하고, 데이터에 결손과 부정합이 없음을 보증하는 것
- 데이터베이스에 저장된 값과 그것이 표현하는 현실의 비즈니스 모델의 값이 일치하는 정확성을 의미함
- 데이터 무결성을 유지하는 것이 데이터베이스 관리 시스템에 중요한 기능
● 데이터 무결성 종류
- 개체 무결성 : 테이블의 기본키를 구성하는 컬럼(속성)은 NULL값이나 중복값을 가질 수 없음
- 참조 무결성 : 외래키 값은 NULL이거나 참조 테이블의 기본키 값과 동일해야 한다.
(외래키란 참조 테이블의 기본키에 정의된 데이터만 허용되는 구조이므로) - 도메인 무결성 : 주어진 속성 값이 정의된 도메인에 속한 값 이어야 함
- NULL 무결성 : 특정 속성에 대해 NULL을 허용하지 않는 특징
- 고유 무결성 : 특정 속성에 대해, 값이 중복되지 않는 특징
- 키 무결성 : 하나의 릴레이션(관계)에는 적어도 하나의 키가 존재해야 함
(테이블이 서로 관계를 가질 경우 반드시 하나 이상의 조인키를 가짐)
※ 도메인 : 각 컬럼(속성)이 갖는 범위
※ 릴레이션 : 테이블간 관계를 말함
※ 튜플 : 하나의 행을 의미함
※ 키 : 식별자
● ERD(Entity Relationship Diagram)
- ERD란 테이블 간 서로의 상관관계를 그림으로 표현한 것
- ERD 구성요소에는 엔티티(Entity), 관계(Relationship), 속성(Attribute)가 있다
-> 현실 세계의 데이터는 이 3가지의 구성으로 모두 표현 가능
2. SELECT문
● SQL 종류
- SQL은 그 기능에 따라 다음과 같이 구분함
| 구분 | 종류 |
| DDL (Data Definition Language) |
CREATE, ALTER, DROP, TRUNCATE |
| DML (Data Manipulation Language) |
INSERT, DELETE, UPDATE, MERGE |
| DCL (Data Control Language) |
GRANT, REVOKE |
| TCL (Transaction Control Language) |
COMMIT, ROLLBACK |
| DQL (Data Query Language) |
SELECT |
※ 사실 SELECT문은 따로 SQL 종류 중 어디에도 속하지 않아서 SELECT문을 위한 DQL 등장
● SELECT문 구조
- SELECT문은 다음과 같이 6개의 절로 구성
- 각 절의 순서대로 작성해야 함(GROUP BY와 HAVING은 서로 바꿀 수 있지만 보통 사용하지 않음)
- SELECT문은 내부 파싱(문법적 해석) 순서는 나열된 순서와는 다름
- FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY 순으로 실행됨
SELECT * or 컬럼명 or 표현식
FROM 테이블명 또는 뷰명
WHERE 조회 조건
GROUP BY 그룹핑컬럼명
HAVING 그룹핑 필터링 조건
ORDER BY 정렬컬럼명
● SELECT절
- SELECT 문장을 사용하여 블러올 컬럼명, 연산 결과를 작성하는 절
- *를 사용하여 테이블 내 전체 컬럼명을 불러올 수 있음
- 원하는 컬럼을 .로 나열하여 작성 가능(순서대로 출력됨)
- 표현식이란 원래의 컬럼명을 제외한 모든 표현 가능한 대상(연산식, 기존 컬럼의 함수 변형식 포함)
** 문법
SELECT * | 컬럼명 | 표현식
FROM 테이블명 또는 뷰명
** 특징
- SELECT절에서 표시할 대상 컬럼에 Alias(별칭) 지정 가능
- 대소문자를 구분하지 않아도 인식한다.
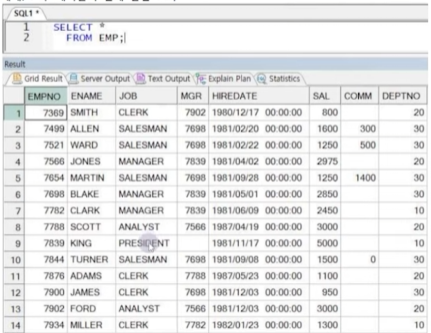
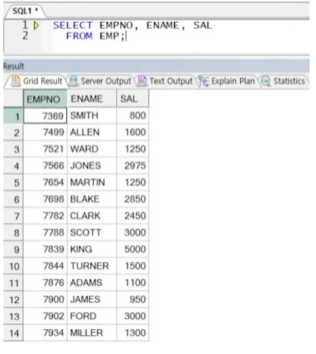
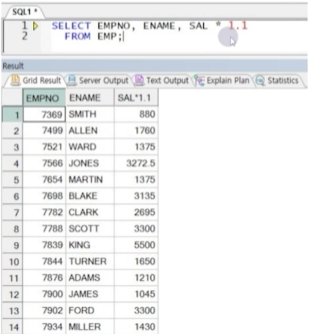
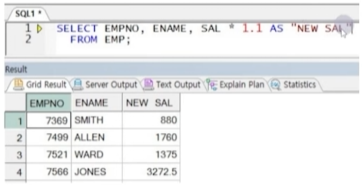
☞ SAL * 1.1이란 컬럼은 없지만 기존 컬럼의 값을 사용하여 연산결과를 SELECT절에서 정의하여 출력할 수 있음.
이런 표현 가능한 모든 수식을 표현식이라고 함(함수식, 연산식 등)
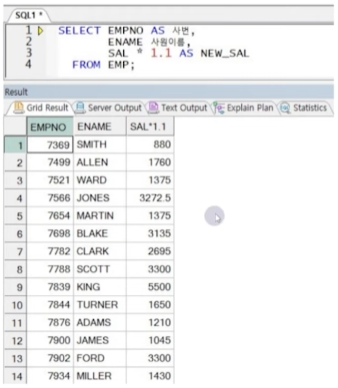
● 컬럼 Alias(별칭)
- 컬럼명 대신 출력할 임시 이름 지정(SELECT절에서만 정의 가능, 원본 컬럼명은 변경되지 않음)
- 컬럼명 뒤에 AS와 함께 컬럼 별칭 전달(AS는 생략 가능)
● 특징 및 주의사항
- SELECT문보다 늦게 수행되는 ORDER BY절에서만 컬럼 별칭 가능(그 외 절에서 사용 시 에러 발생)
- 한글 사용 가능(한글 지원 캐릭터셋 설정 시)
- 이미 존재하는 예약어는 별칭으로 사용 불가
ex) avg, count, decode, SELECT, FROM 등... - 다음의 경우 별칭에 반드시 쌍따옴표 전달 필요
- 별칭에 공백을 포함하는 경우
- 별칭에 특수문자를 포함하는 경우("_" 제외)
- 별칭 그대로 전달할 경우(입력한 대소를 그대로 출력하고자 할 때)
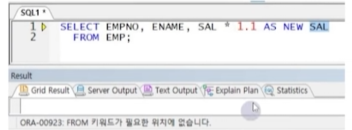
☞ 공백 작성 시 쌍따옴표를 사용하지 않아 에러 발생
● FROM절
- 데이터를 불러올 테이블명 또는 뷰명 전달
- 테이블 여러 개 전달 가능(컴마로 구분) -> 조인 조건 없이 테이블명만 나열 시 카타시안 곱 발생 주의!
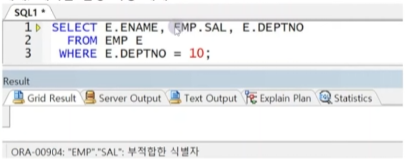
- 테이블 별칭 선언 가능(ORACLE은 AS 사용 불가, SQL Server는 사용/생략 가능)
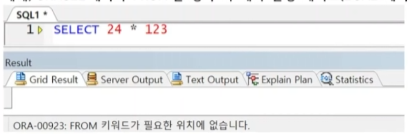
※ 테이블 별칭 선언 시 컬럼 구분자는 테이블 별칭으로만 전달(테이블명으로 사용 시 에러 발생) - ORACLE에서는 FROM절 생략 불가(의미상 필요없는 DUAL 테이블 선언)
※ ORACLE 23c 버전부터는 생략 가능 - SQL Server에서는 FROM절 필요없을 경우 생략 가능(오늘 날짜 조회 시)
※ 뷰 : 테이블과 동일하게 데이터를 조회할 수 있는 객체이지만 테이블처럼 실제 데이터가 저장된 것이 아닌, SELECT문 결과에 이름을 붙여 그 이름만으로 조회가 가능하도록 한 기능

3. 함수
● 함수 정의
- input value가 있을 경우 그에 맞는 output value를 출력해주는 객체
- input value와 output value의 관계를 정의한 객체
- from절을 제외한 모든 절에서 사용 가능
● 함수 기능
- 기본적인 쿼리문을 더욱 강력하게 해줌
- 데이터의 계산을 수행
- 개별 데이터의 항목을 수정
- 표시할 날짜 및 숫자 형식을 지정
- 열 데이터의 유형(data type)을 변환
● 함수의 종류(입력값의 수에 따라)
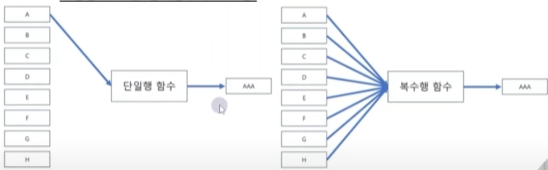
- 단일행 함수와 복수행 함수로 구분
- 단일행 함수 : input과 output의 관계가 1:1
- 복수행 함수 : 여러 건의 데이터를 동시에 입력 받아서 하나의 요약값을 리턴
(그룹함수 또는 집계함수라고도 함)
● 입/출력값의 타입에 따른 함수 분류
- 문자형 함수
- 문자열 결합, 추출, 삭제 등을 수행
- 단일행 함수 형태
- output은 대부분 문자값(LENGTH, INSTR 제외)
※ 문자 함수 종류
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
| LOWER(대상) | 문자열을 소문자로 | LOWER('ABC') | abc | |
| UPPER(대상) | 문자열을 대문자로 | UPPER('abc') | ABC | |
| SUBSTR(대상, m, n) | 문자열 중 m위치에서 n개의 문자열 추출 | SUBSTR('ABCED',2,3) | BCD | |
| SUBSTR('ABCED',2) | BCDE | n 생략 시 끝까지 추출 | ||
| SUBSTR('ABCED',-4,3) | BCD | 뒤에서 4번째(B)부터 오른쪽으로 스캔하여 3개의 문자열 추출 | ||
| INSTR(대상, 찾을문자열, m, n) | 대상에서 찾을 문자열 위치 반환(m위치에서 시작, n번째 발견된 문자열 위치까지) | INSTR('A#B#C#', '#') | 2 | m과 n 생략 시 1로 해석 |
| INSTR('A#B#C#', '#', 3, 2) | 6 | 3번째부터 두번째 발견된 # 위치 | ||
| INSTR('A#B#C#','#',-3,2) | 2 | 뒤에서 3번째(#)에서 왼쪽으로 스캔하여 두번째로 발견된 #의 위치 리턴 | ||
| LTRIM(대상, 삭제문자열) | 문자열 중 특정 문자열을 왼쪽에서 삭제 | LTRIM('AABABAA','A') | BABAA | 삭제문자열 생략 시 공백 삭제 |
| RTRIM(대상, 삭제문자열) | 문자열 중 특정 문자열을 오른쪽에서 삭제 | RTRIM('AABABAA', 'A') | AABAB | 삭제문자열 생략 시 공백 삭제 |
| TRIM(대상) | 문자열 중 특정 문자열을 양쪽에서 삭제 | TRIM(' ABCDE ') | ABCED | ORACLE TRIM은 공백만 삭제 가능 |
| LPAD(대상, n, 문자열) | 대상 왼쪽에 문자열을 추가하여 총 n의 길이 리턴 | LPAD('ABC', 5, '*') | **ABC | |
| RPAD(대상, n, 문자열) | 대상 오른쪽의 문자열을 추가하여 총 n의 길이 리턴 | RPAD('ABC', 5, '*') | ABC** | |
| CONCAT(대상1, 대상2) | 문자열 결합 | CONCAT('A', 'B') | AB | 두 개의 인수만 전달 가능 |
| LENGTH(대상) | 문자열 길이 | LENGTH('ABCDE') | 5 | |
| REPLACE(대상, 찾을 문자열, 바꿀 문자열) | 문자열 치환 및 삭제 | REPLACE('ABBA', 'AB' ,'ab') | abBA | 세번째 인수를 생략하거나 빈 문자열 전달 시 찾을 문자열 삭제 가능 |
| TRANSLATE(대상, 찾을 문자열, 바꿀 문자열) | 글자를 1:1로 치환 | TRANSLATE('ABBA', 'AB', 'ab') | abba | 매칭되는 글자끼리 치환(A는 a로, B는 b로), 바꿀 문자열 생략 불가, 빈 문자열 전달 시 NULL 리턴 |
● SQL Server)
- SUBSTR -> SUBSTRING
- LENGTH -> LEN
- INSTR -> CHARINDEX.
2. 숫자형 함수
- 숫자를 입력하면 숫자 값을 반환
- 단일행 함수 형태의 숫자함수
- ORACLE과 SQL Server 함수 거의 동일
※ 숫자 함수 종류
| 함수명 | 함수 기능 | 사용 예시 | 출력 | 기타 설명 |
| ABS(숫자) | 절대값 변환 | ABS(-1.5) | 1.5 | |
| ROUND(숫자, 자리수) | 소수점 특정 자리에서 반올림 | ROUND(123.456, 2) | 123.46 | 소수점 둘째자리로 반올림 |
| ROUND(123.456, -2) | 100 | 자리가 음수이면 정수자리에서 반올림(백의 자리) | ||
| TRUNC(숫자, 자리수) | 소수점 특정 자리에서 버림 | TRUNC(123.456, 2) | 123.45 | |
| SIGN(숫자) | 숫자가 양수면 1, 음수면 -1, 0이면 0 반환 | SIGN(100) | 1 | |
| FLOOR(숫자) | 작거나 같은 최대 정수 리턴 | FLOOR(3.5) | 3 | |
| CEIL(숫자) | 크거나 같은 최소 정수 리턴 | CEIL(3.5) | 4 | |
| MOD(숫자 1, 숫자 2) | 숫자1을 숫자2로 나누어 나머지 반환 | MOD(7, 2) | 1 | |
| POWER(m, n) | m의 n 거듭 제곱 | POWER(2, 4) | 16 | |
| SQRT(숫자) | 루트값 리턴 | SQRT(16) | 4 |
3. 날짜형 함수
- 날짜 연산과 관련된 함수
- ORACLE과 SQL Server 함수 거의 다름
※ 날짜 함수 종류
| 함수명 | 함수 기능 | 사용 예시 | 출력 | 기타 설명 |
| SYSDATE | 현재 날짜와 시간 리턴 | SYSDATE | 2024/08/05 19:23:34 | 날짜 출력 형식에 따라 다르게 출력됨(날짜만 출력되게 될 수 있음) |
| CURRENT_DATE | 현재 날짜 리턴 | CURRENT_DATE | 2024/08/05 | 날짜 출력 형식에 따라 다르게 출력됨(시간이 출력될 수 있음) |
| CURRENT_TIMESTAMP | 현재 타임스태프 리턴 | CURRENT_TIMESTAMP | 2024/08/05 19:23:34 +09:00 | |
| ADD_MONTH(날짜, n) | 날짜에서 n개월 후 개날짜 리턴 | ADD_MONTH(SYSDATE, 3) | 2024/11/05 19:23:34 | n이 음수인 경우 n개월 전 날짜 리턴 |
| MONTH_BETWEEN(날짜1, 날짜2) | 날짜1과 날짜2의 개월 수 리턴 | MONTH_BETWEEN (SYSDATE, HIREDATE) | 3.7234 | 날짜1 < 날짜2로 전달 시 음수 리턴 |
| LAST_DAY(날짜) | 주어진 월의 마지막 날짜 리턴 | LAST_DAY(SYSDATE) | 2024/08/31 19:23:24 | |
| NEXT_DAY(날짜, n) | 주어진 날짜 이후 지정된 요일의 첫 번째 날짜 리턴 | NEXT_DAY(SYSDATE, 3) | 2024/08/06 19:23:34 | 1: 일요일 ~ 7 : 토요일 |
| ROUND(날짜, 자리수) | 날짜 반올림 | ROUND(SYSDATE, 'MONTH') | 2024/08/01 0:00 | 월 이전자리에서 반올림 |
| TRUNC(날짜, 자리수) | 날짜 버림 | TRUNC(SYSDATE, 'MONTH') | 2024/08/01 0:00 | 월 이전자리에서 버림 |
● SQL Server)
- SYSDATE -> GETDATE
- ADD_MONTHS -> DATEADD(월 뿐만 아니라 모든 단위 날짜 연산 가능)
- MONTHS_BETWEEN -> DATEDIFF(두 날짜 사이의 년, 월, 일 추출)
4. 변환 함수
- 값의 데이터 타입을 변환
- 문자를 숫자로, 숫자를 문자로, 날짜를 문자로 변경
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
| TO_NUMBER | 숫자타입으로 변경 | TO_NUMBER('100') | 100 | 문자 100을 숫자 100으로 리턴 |
| TO_CHAR(대상, 포멧) | 1) 날짜의 포멧 변경 | TO_CHAR(SYSDATE, 'MM-DD-YYYY') | 08-05-2024 | 날짜 형식 리턴(타입은 문자) |
| 2) 숫자의 포멧 변경 | TO_CHAT(9000, '9,999') | 9,000 | 천단위 구분 기호 생성(타입은 문자) | |
| TO_DATE(문자, 포멧) | 주어진 문자를 포멧 형식에 맞게 읽어 날짜로 리턴 | TO_DATE('2024/08/05', 'YYYY-MM-DD') | 2024-08-05 00:00:00 | 날짜로 리턴됌 |
| FORMAT(날짜, 포멧) | 날짜의 포멧 변경 | FORMAT(GETDATE(), 'YYYY') | 2024 | SQL SERVER 함수 |
| CAST(대상 AS 데이터 타입) | 대상을 주어진 데이터타입으로 변환 | CAST('100' AS int) | 100 | 문자 100을 숫자 100으로 리턴 |
● SQL Server)
- TO_NUMBER, TO_DATE, TO_CHAR -> CONVERT(포멧 전달 시)
- 단순 변환일 경우 CAST 사용
5. 그룹 함수
- 다중행 함수
- 여러 값이 input값으로 들어가서 하나의 요약된 값으로 리턴
- GROUP BY와 함께 자주 사용됨
- ORACLE과 SQL Server 거의 동일
| 함수명 | 함수 기능 | 사용 예시 | 출력 | 기타 설명 |
| COUNT(대상) | 행의 수 리턴 | SELECT COUNT(SAL) FROM EMP; | 각 연산 결과 | NULL 무시하고 연산 |
| SUM(대상) | 총 합 리턴 | SELECT SUM(SAL) FROM EMP; | 각 연산 결과 | NULL 무시하고 연산 |
| AVG(대상) | 평균 리턴 | SELECT AVG(SAL) FROM EMP; | 각 연산 결과 | NULL 무시하고 연산 |
| MIN(대상) | 최솟값 리턴 | SELECT MIN(SAL) FROM EMP; | 각 연산 결과 | NULL 무시하고 연산 |
| MAX(대상) | 최댓값 리턴 | SELECT MAX(SAL) FROM EMP; | 각 연산 결과 | NULL 무시하고 연산 |
| VARIANCE(대상) | 분산 리턴 | SELECT VARIANCE(SAL) FROM EMP; | 각 연산 결과 | NULL 무시하고 연산 |
| STDDEV(대상) | 표준 편차 리턴 | SELECT STDDEV(SAL) FROM EMP; | 각 연산 결과 | NULL 무시하고 연산 |
● SQL Server)
- VIRIANCE -> VAR
- STDDEV -> STDEV
6. 일반 함수
- 기타 함수(널 치환 함수 등)
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
| DECODE(대상, 값1, 리턴1, 값2, 리턴2..., 그 외 리턴) | 대상의 값이 1이면 리턴 1, 값이 2면 리턴 2 ... 그 외에는 그외 리턴값 출력 | DECODE(DEPTNO, 10, A, B) | A 또는 B | 대소 비교에 따른 치환 불가, 그 외 리턴 생략 시 NULL 리턴 |
| NVL(대상, 치환값) | 대상이 NULL이면 치환값으로 치환하여 리턴 | NVL(COMM, 0) | COMM값 또는 0 리턴 | |
| NVL2(대상, 치환값1, 치환값2) | 대상이 NULL이면 치환값2로 리턴, NULL이 아니면 치환값 1로 리턴 | NVL2(COMM, COMM*1.1, 0) | COMM*1.1 또는 0 리턴 | COMM값이 NULL 이면 0, NULL이 아니면 COMM*1.1 리턴 |
| COALESCE(대상 1, 대상 2, ... 그 외 리턴) | 대상들 중 널이 아닌 값 출력(가장 첫번째부터) 모두가 널이면 그 외 리턴값이 리턴 | COALESCE(NUL, 100) | 100 | 그 외 리턴 값 생략 시 NULL 리턴 |
| ISNULL(대상, 치환값) | 대상이 NULL이면 치환값 리턴 | ISNULL(NULL, 100) | 100 | SQL Server함수 |
| NULLIF(대상1, 대상2) | 두 값이 같으면 NULL리턴, 다르면 대상1 리턴 | NULLIF(10, 20) | 10 | |
| CASE문 | 조건별 치환 및 연산 수행 | 아래 하단 참고 | 아래 하단 참고 |
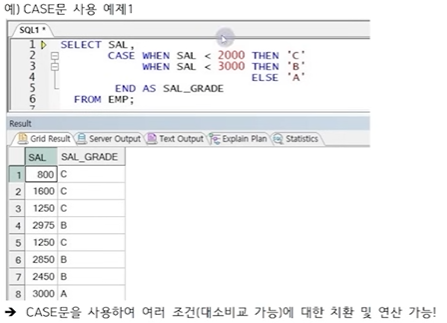
4. WHERE절
● WHERE절
- 테이블의 데이터 중 원하는 조건에 맞는 데이터만 조회하고 싶을 경우 사용(엑셀의 필터기능과 유사)
- 여러 조건 동시 전달 가능(AND 와 OR로 조건 연결)
- NULL 조회 시 IS NULL / IS NOT NULL 연산자 사용( = 연산자로 조회 불가)
- 연산자를 사용하여 다양한 표현이 가능
- 조건 전달 시 비교 대상의 데이터 타입은 일치하는 것이 좋음
ex) EMP 테이블의 부서번호 컬럼의 데이터 타입은 숫자인데 문자 상수로 비교 시 성능 문제가 발생할 수 있음
| 연산자 종류 | 설명 |
| = | 같은 조건을 검색 |
| !=, <> | 같지 않은 조건을 검색 |
| > | 큰 조건을 검색 |
| >= | 크거나 같은 조건을 검색 |
| < | 작은 조건을 검색 |
| <= | 작거나 같은 조건을 검색 |
| BETWEEN a AND b | A와 B 사이에 있는 범위 값을 모두 검색 |
| IN(a,b,c) | A거나 B거나 C인 조건을 검색 |
| LIKE | 특정 패턴을 가지고 있는 조건을 검색 |
| IS NULL, IS NOT NULL | NULL 값을 검색 / NULL이 아닌 값을 검색 |
| A AND B | A 조건과 B조건을 모두 만족하는 값만 검색 |
| A OR B | A 조건이나 B 조건 중 한가지라도 만족하는 값을 검색 |
| NOT A | A가 아닌 모든 조건을 검색 |
SELECT * | 컬럼명 | 표현식
FROM 테이블명 또는 뷰명
WHERE 조회할 데이터 조건
** 주의사항
- 문자나 날짜 상수 표현 시 반드시 홀따옴표 사용(다른 절에서도 동일 적용)
- ORACLE은 문자 상수의 경우 대소문자 구분
- MSSQL은 기본적으로 문자상수의 대소문자를 구분하지 않음
● IN 연산자
- 포함연산자로 여러 상수와 일치하는 조건 전달 시 사용
- 상수를 괄호로 묶어서 동시에 전달(문자와 날짜 상수의 경우 반드시 홀따옴표와 함께)
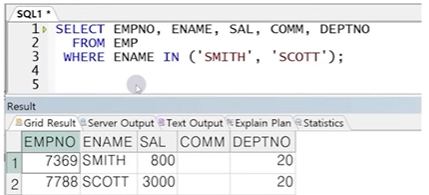
☞ IN연산자를 사용하면 조건대상(ENAME)과 연산자(=)의 반복을 줄일 수 있음
이 때, ()안의 상수도 문자 상수와 날짜 상수는 홀따옴표 필수
● BETWEEN A AND B 연산자
- A보다 크거나 같고 B보다 작거나 같은 조건을 만족
- A와 B에는 범위로 묶을 상수값 전달(문자, 숫자, 날짜 모두 전달 가능)
- 반드시 A가 B보다 작아야 함(반대로 작성 시 아무것도 출력되지 않음)

● LIKE 연산자
- 정확하게 일치하지 않아도 되는 패턴 조건 전달 시 사용
- %와 _와 함께 사용
- % : 자리 수 제한 없는 모든이라는 의미
- _ : _ 하나 당 한 자리 수를 의미하며 모든 값을 표현함
ex)
ENAME LIKE 'S%' : ENAME이 S로 시작하는
ENAME LIKE '%S%' : ENAME에 S를 포함하는
ENAME LIKE '%S' : ENAME이 S로 끝나는
ENAME LIKE '_S%' : ENAME의 두번째 글자가 S인(맨 앞이 _인 것 주의!, %면 자리 수 상관 없이 S를 포함하기만 하면 됌)
ENAME LIKE '_ _S_ _' : ENAME의 가운데 글자가 S이며 이름의 길이가 5글자인
● NOT 연산자
- 조건 결과의 반대 집합. 즉, 여집합을 출력하는 연산자
- NOT 뒤에 오는 연산 결과의 반대 집합 출력
- 주로 NOT IN, NOT BETWEEN A AND B, B NOT LIKE, NOT NULL로 사용
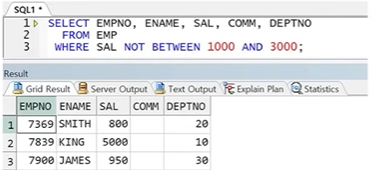
☞ 1000 이상 3000 이하의 반대 집합 -> 1000미만 또는 3000 초과
5. GROUP BY절과 HAVING절
● GROUP BY절
- 각 행을 특정 조건에 따라 그룹으로 분리하여 계산하도록 하는 구문식
- GROUP BY절에 그룹을 지정할 컬럼을 전달(여러 개 가능)
- 만약 그룹 연산에서 제외할 대상이 있다면 미리 WHERE절에서 해당 행을 제외함
(WHERE절이 GROUP BY절보다 먼저 수행되므로) - 그룹에 대한 조건은 WHERE절에서 사용할 수 없음
- SELECT절에 집계 함수를 사용하여 그룹 연산 결과 표현
- GROUP BY절을 사용하면 데이터가 요약되므로 요약되기 전 데이터와 함께 출력할 수 없음
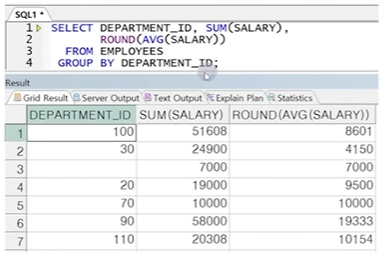
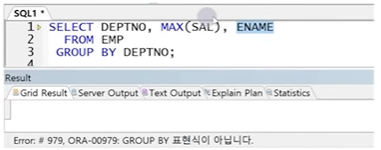
☞ GROUP BY 절에 DEPTNO를 사용하면 DEPTNO가 같은 값끼리 묶여서 요약 정보만 SELECT절에 표현 가능.
따라서 GROUP BY 컬럼과 집계 함수를 사용한 결과만이 전달 가능
-> GROUP BY절에 명시되지 않은 컬럼 전달 불가
● HAVING 절
- 그룹 함수 결과를 조건으로 사용할 때 사용하는 절
- WHERE절을 사용하여 그룹을 제한할 수 없으므로 HAVING 절에 전달
- HAVING절이 GROUP BY절 앞에 올 수는 있지만 뒤에 쓰는 것을 권장
- 내부적 연산 순서가 SELECT절보다 먼저이므로 SELECT절에서 선언된 Alias 사용 불가
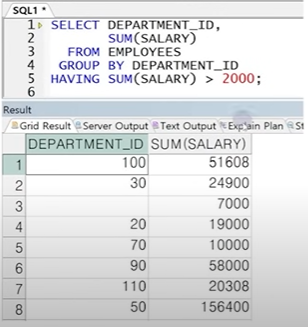
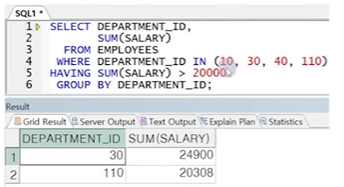
☞ 순서상 WHERE절을 먼저 수행, 원하는 데이터만 필터링 한 후 GROUP BY에 의해 그룹 연산을 수행한 뒤 HAVING절에서 만족하는 데이터만 선택하여 출력
6. ORDER BY 절
● ORDER BY 절
- 데이터는 입력된 순서대로 출력되나, 출력되는 행의 순서를 사용자가 변경하고자 할 때 ORDER BY 절을 사용
- ORDER BY 뒤에 명시된 컬럼 순서대로 정렬 -> 1차 정렬, 2차 정렬 전달 가능
- 정렬 순서를 오름차순(ASC), 내림차순(DESC)으로 전달(생략 시 오름차순 정렬)
- 유일하게 SELECT 절에 정의한 컬럼 별칭 사용 가능
- SELECT 절에 선언된 순서대로 숫자 전달 가능(컬럼명과 숫자 혼합 사용 가능)
● 정렬 순서(오름차순)
- 한글 : 가, 나, 다, 라 ...
- 영어 : A, B, C, D ...
- 숫자 : 1, 2, 3, 4 ...
- 날짜 : 과거 날짜부터 시작애서 최근 날짜로 정렬
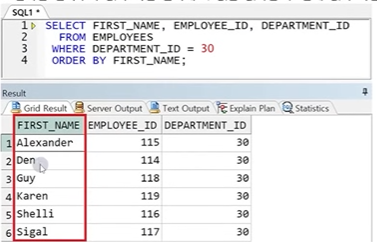
※ 문자는 왼쪽부터 값이 작은 순서대로 같은 값이면 두 번째 값이 작은 순서대로 정렬된다.

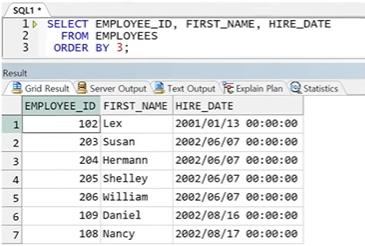
● 복합 정렬
- 먼저 정렬한 값의 동일한 결과가 있을 경우 추가적으로 정렬 가능
-> 1차 정렬한 값이 같은 경우 그 값 안에서 2차 정렬 컬럼값의 정렬이 일어남
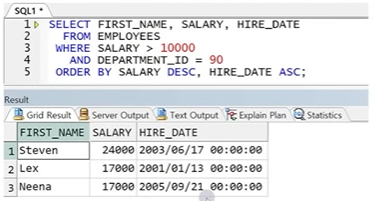
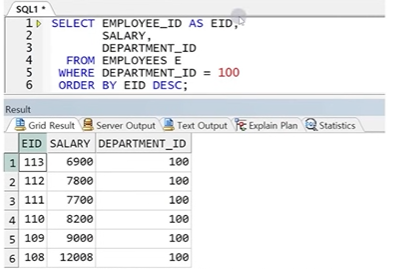
☞ SELECT절보다 늦게 수행되는 구문은 ORDER BY절 뿐이므로 ORDER BY절만 SELECT절에서 정의된 컬럼 별칭 사용 가능
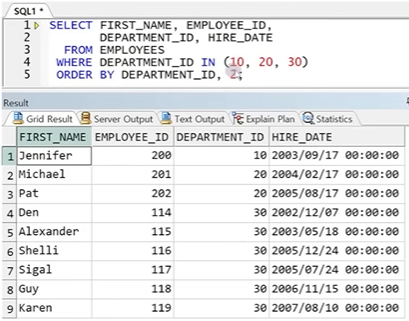
● NULL의 정렬
- NULL을 포함한 값이 정렬 시 ORACLE은 기본적으로 NULL을 마지막에 배치(SQL Server는 처음애 배치)
- ORACLE은 ORDER BY절에 NULLS LAST | NULLS FIRST을 명시하여 NULL 정렬 순서 변경 가능

☞ NULLS LAST가 기본이므로 NULL이 마지막에 배치
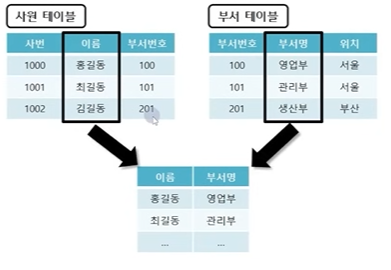
7. 조인
● JOIN(조인)
- 여러 테이블의 데이터를 사용하여 동시 출력하거나 참조 할 경우 사용
- FROM절에 조인할 테이블 나열
- ORACLE 표준은 테이블 나열 순서 중요하지 않음, ANSI 표준은 OUTER JOIN시 순서 중요
- WHERE절에서 조인 조건을 작성(ORACLE 표준)
- 동일한 열 이름이 여러 테이블에 존재할 경우 열 이름 앞에 테이블 이름이나 테이블 Alias 붙임
- N개의 테이블을 조인하려면 최소 N-1개의 조인 조건이 필요
- ORACLE 표준과 ANSI 표준이 서로 다름
● 조인 종류
- 조건의 형태에 따라
- ) EQUI JOIN(등가 JOIN) : JOIN 조건이 동등 조건인 경우
- ) NON EQUI JOIN : JOIN조건이 동등 조건이 아닌 경우
- 조인 결과에 따라
- ) INNER JOIN : JOIN 조건에 성립하는 데이터만 출력하는 경우
- ) OUTER JOIN : JOIN 조건에 성립하지 않는 데이터도 출력하는 경우
(LEFT / RIGHT / FULL OUTER JOIN으로 나뉨) - ) NATURAL JOIN : 조인 조건 생략 시 두 테이블에 같은 이름이로 자연 연결되는 조인
- ) CROSS JOIN : 조인 조건 생략 시 두 테이블의 발생 가능한 모든 행을 출력하는 조인
- ) SELF JOIN : 하나의 테이블을 두 번 이상 참조하여 연결하는 조인
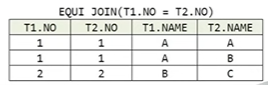
● EQUI JOIN(등가 조인)
- 조인 조건이 '='(equal) 비교를 통해 같은 값을 가지는 행을 연결하여 결과를 얻는 조인 방법
- SQL 명령문에서 가장 많이 사용하는 조인 방법
- FROM절에 조인하고자 하는 테이블을 모두 명시
- FROM절에 명시하는 테이블은 별칭(Alias) 사용 가능
- WHERE절에 두 테이블의 공통 컬럼에 대한 조인 조건을 나열

** 문법(ORACLE 표준)
SELECT 테이블1.컬럼, 테이블2.컬럼
FROM 테이블1, 테이블2
WHERE 테이블1.컬럼 = 테이블2.컬럼;
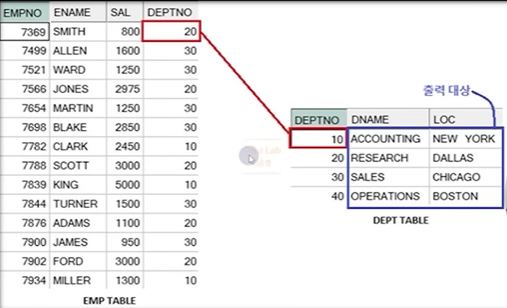
정답 :
SELECT EMP.ENAME, DEPT.DNAME
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
● NON - EQUI JOIN(등가 조인)
- 테이블을 연결짓는 조인 컬럼에 대한 비교 조건이 '<', BETWEEN A AND B와 같이 '=' 조건이 아닌 연산자를 사용하는 경우의 조인조건
** 문법(ORACLE 표준)
SELECT 테이블1.컬럼, 테이블2.컬럼
FROM 테이블1, 테이블2
WHERE 테이블1.컬럼 비교조건 테이블2.컬럼;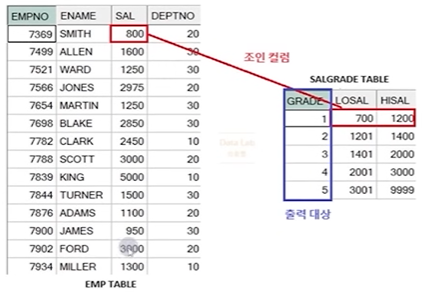
정답 :
SELECT E.ENAME, E.SAL, S.GRADE
FROM EMP E, SAL_GRADE S
WHERE E.SAL BETWEEN S.LOSAL AND S.HISAL;
● 세 테이블 이상의 조인
- 관계를 잘 파악하여 모든 테이블이 연결되도록 조인 조건 명시
- N개 테이블의 경우 최소 N-1개의 조인 조건 필요
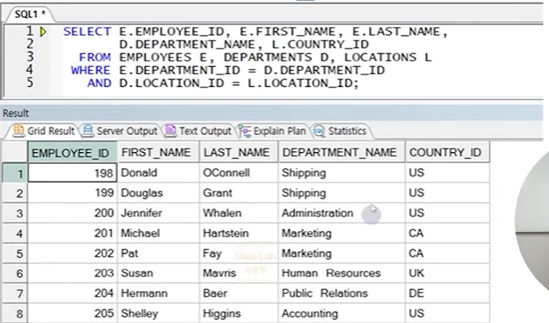
● SELF JOIN
- 한 테이블 내 각 행끼리 관게를 갖는 경우 조인 기법
- 한 테이블을 참조할 때마다(필요할 때마다) 명시해야 함
- 테이블명이 중복되므로 반드시 테이블 명칭 사용

정답 :
SELECT E1.EMPLOYEE_ID, E1.FITSR_NAME, E1.LAST_NAME, E1.MANAGER_ID
E2.EMPLOYEE_ID, E2.FITSR_NAME, E2.LAST_NAME
FROM EMPLOYEES E1, EMPLOYEES E2
WHERE E1.MANAGER_ID = E2.EMPLOYEE_ID
ORDER BY 1, 4;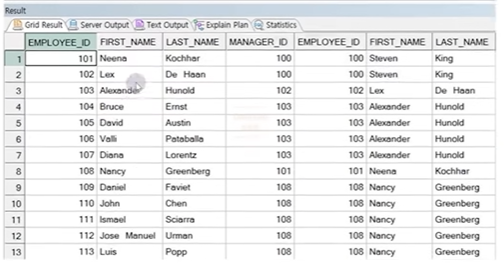
응용 예제) EMP 테이블에서 상위관리자(매니저)보다 급여가 많은 직원 출력
- 중요 1) 테이블 한 번 스캔 시(한 행만 읽었을 경우) 매니저 정보는 없으므로 셀프 조인 필요
- 중요 2) 원하는 정보를 모두 한 행으로 출력 후 조건 선택 가능
- 중요 3) 조인 조건과 일반 조건을 각자의 위치에서 전달
(ORACLE은 모두 WHERE절 기술, ANSI 표준은 조인 조건은 ON 절, 일반 조건만 WHERE절)
SELECT E1.EMPNO, E1.ENAME, E1.SAL,
E2.EMPNO, E2.ENAME, E2.SAL
FROM EMP E1, EMP E2
WHERE E1.MGR = E2.EMPNO
AND E1.SAL > E2.SAL;
8. 표준 조인
● 표준 조인
- ANSI 표준으로 작성되는 INNER JOIN, CROSS JOIN, NATURAL JOIN, OUTER JOIN을 말함
● INNER JOIN
- 내부 조인이라고 하며, 조인 조건이 일지하는 행만 추출(ORACLE 조인 기본)
- ANSI 표준의 경우 FROM 절에 INNER JOIN 혹은 JOIN을 명시
- ANSI 표준의 경우 USING 이나 ON 조건절을 필수적으로 사용
● ON 절
- 조인할 양 컬럼의 컬럼명이 서로 다르더라고 사용 가능
- ON 조건의 괄호는 옵션(생략 가능)
- 컬럼명이 같을 경우 테이블 이름이나 별칭을 사용하여 명확하게 지정(테이블 출처 명확히)
- ON 조건절에서 조인 조건 명시, WHERE 절에서는 일반 조건 명시(WHERE 절과 ON 절을 쓰임에 따라 명확히 구분)
** 문법
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 INNER JOIN 테이블2
ON 테이블1.조인컬럼 = 테이블2.조인컬럼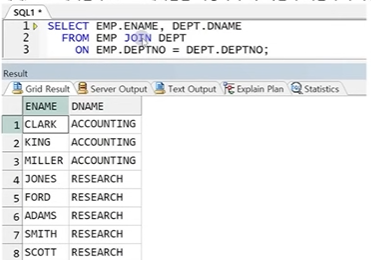
☞ ORACLE 표준은 FROM절에 테이블을 컴마로 구성, WHERE절에 조인 조건 나열
ORACLE은 INNER JOIN이 기본 조인 연산이므로 별도의 문법 존재 안함
● USING 조건절
- 조인할 컬럼명이 같을 경우 사용
- Alias나 테이블 이름 같은 접두사 붙이기 불가
- 괄호 필수
** 문법
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 INNER JOIN 테이블2
USING (동일 컬럼명);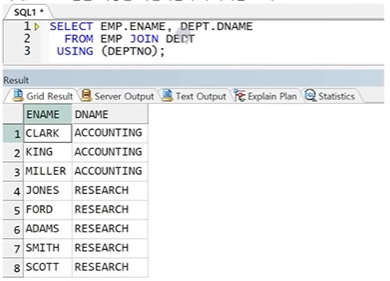
● NATURAL JOIN
- 두 테이블 간의 동일한 이름을 가지는 모든 컬럼들에 대해 EQUI JOIN을 수행
- USING, ON, WHERE절에서 조건 정의 불가
- JOIN에 사용된 컬럼들은 데이터 유형이 동일해야 하며 접두사 사용 불가

** 문법
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 NATURAL JOIN 테이블2;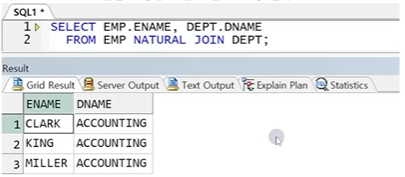
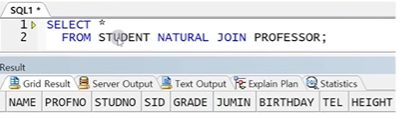
☞ NATURAL JOIN은 동일한 이름의 모든 컬럼을 조인 컬럼으로 사용하므로 조인 컬럼의 값이 모두 같을 때만 결과가 리턴됨
☞ STUDENT와 PROFESSOR 테이블에는 NAME컬럼과 PROFNO컬럼의 컬럼명이 서로 동일
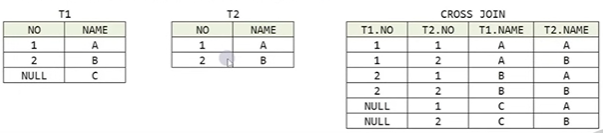
● CROSS JOIN
- 테이블 간 JOIN 조건이 없는 경우 생성 가능한 모든 데이터들의 조합(카타시안 곱 출력)
- 양 쪽 테이블 행의 수의 곱한 수의 데이터 조합 발생(m * n)
** 문법
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 CROSS JOIN 테이블2;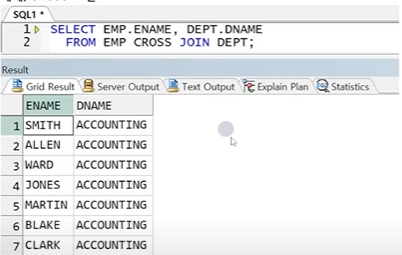
☞ 내용이 길어 일부만 출력했지만, 총 56건이 출력됨(EMP 14건, DEPT 4건이므로 14X4 = 56)
● OUTER JOIN
- INNER JOIN과 대비되는 조인 방식
- JOIN 조건에서 동일한 값이 없는 행도 반환할 때 사용
- 두 테이블 중 한쪽에 NULL을 가지면 EQUI JOIN 시 출력되지 않음 -> 이를 출력 시 OUTER JOIN 사용
- 테이블 기준 방향에 따라 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN으로 구분
- OUTER 생략 가능(LEFT OUTER JOIN -> LEFT JOIN)
** OUTER JOIN 종류
- LEFT OUTER JOIN
- FROM 절에 나열된 왼쪽 테이블에 해당하는 데이터를 읽은 후, 우측 테이블에서 JOIN 대상 읽어옴
- 즉, 왼쪽 테이블이 기준이 되어 오른쪽 테이블 데이터를 채우는 방식
- 우측 값에서 같은 값이 없는 경우 NULL 값으로 출력
- RIGHT OUTER JOIN
- LEFT OUTER JOIN의 반대
- 즉, 오른쪽 테이블 기준으로 왼쪽 테이블 데이터를 채우는 방식
- FROM 절에 테이블 순서를 변경하면 LEFT OUTER JOIN으로 수행 가능
- FULL OUTER JOIN
- 두 테이블 전체 기준으로 결과를 생성하여 중복 데이터는 삭제 후 리턴
- LEFT OUTER JOIN 결과와 RIGHT OUTER JOIN 결과의 UNION 연산 리턴과 동일함
- ORACLE 표준에는 없음

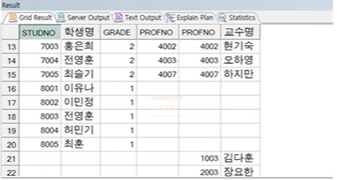
☞ STUDENT, PROFESSOR 테이블을 PROFNO로 연결하면 학생, 지도교수 정보 함께 출력 가능
☞ STUDENT 테이블의 PROFNO가 NULL인 경우는 데이터가 생략됨(INNER JOIN)
☞ 지도교수가 없는 학생 정보 출력 시 OUTER JOIN 수행
☞ 이 때, 기준이 되는 데이터(생략되지 않았으면 하는 쪽)는 STUDENT 테이블 -> LEFT OUTER JOIN
정답 :
ORACLE 표준)
SELECT *
FROM STUDENT S, PROFESSOR P
WHERE S.PROFNO = P.PROFNO(+)
AND S.GRADE IN (1, 4);
ANSI 표준)
SELECT S.STUDNO, S.NAME AS 학생명, S.GRADE, S.PROFNO,
P.PROFNO, P.NAME AS 교수명
FROM STUDENT S LEFT OUTER JOIN PROFESSOR P
ON S.PROFNO = P.PROFNO
WHERE S.GRADE IN (1, 4);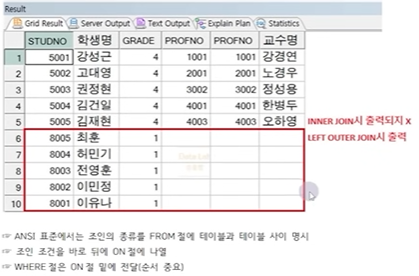
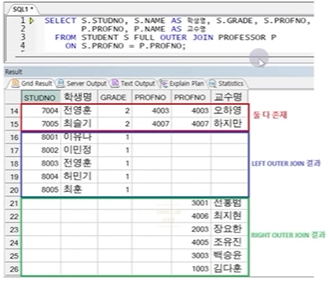
☞ 7004, 7005번 학생 정보는 LEFT OUTER JOIN에서도, RIGHT OUTER JOIN에서도 출력됨
☞ LEFT OUTER JOIN 결과와 RIGHT OUTER JOIN 결과를 동시 출력(중복 데이터는 한번만)
☞ ORACLE 에서는 지원하지 않는 문법((+) 기호를 양 방향 전달 시 에러 발생)
☞ 성능적으로도 좋지 않기 때문에 사용 시 주의 필요
정답 :
ORACLE 문법)
SELECT S.STUDNO, S.NAME AS 학생명, S.GRADE, S.PROFNO
P.PROFNO, P.NAME AS 교수명
FROM STUDENT S, PROFESSOR P
WHERE S.PROFNO = P.PROFNO(+)
UNION
SELECT S.STUDNO, S.NAME AS 학생명, S.GRADE, S.PROFNO
P.PROFNO, P.NAME AS 교수명
FROM STUDENT S, PROFESSOR P
WHERE S.PROFNO(+) = P.PROFNO