SQLD 정리
SQLD 1과목 정리 PART 2
choco2706
2024. 8. 2. 22:07
PART7. 관계와 조인의 이해
● 관계(Relationship)의 개념
- 엔티티의 인스턴스 사이의 논리적인 연관성
- 엔티티의 정의, 속성 정의 및 관계 정의에 따라서도 다양하게 변할 수 있음
- 관계를 맺는다는 부모의 식별자를 자식에 상속하고, 상속된 속성을 매핑키(조인키)로 활용
-> 부모, 자식을 연결함
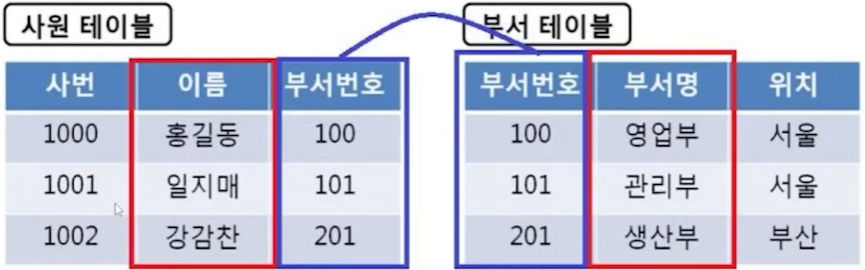
● 관계의 분류
- 관계는 존재에 의한 관계와 행위에 의한 관계로 분류
- 존재 관계는 엔티티 간의 상태를 의미
ex) 사원 엔티티는 부서 엔티티에 소속 - 행위 관계는 엔티티 간의 어떤 행위가 있는 것을 의미
ex) 주문은 고객이 주문할 때 발생
● 조인의 의미
- 결국 데이터의 중복을 피하기 위해 테이블은 정규화에 의해 분리된다.
- 분리되면서 두 테이블은 서로 관계를 맺게 되고, 이 두 테이블의 데이터를 동시에 출력하거나 관계가 있는 테이블을 참조하기 위해서는 데이터를 연결해야 하는데 이 과정을 조인이라고 함
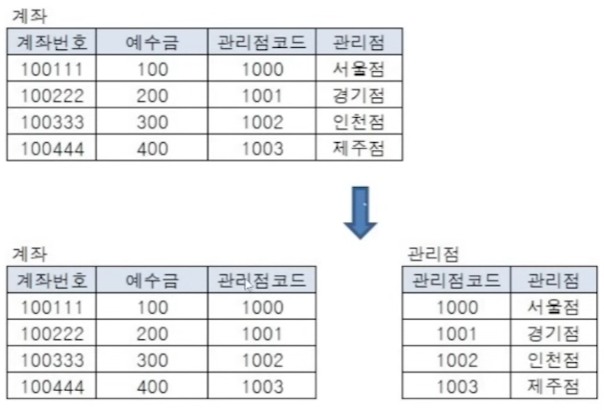
- ex) 계좌번호 100111의 관리점이 어디인지 찾으려면?
- 계좌번호 테이블에서 계좌번호가 100111 데이터 확인
- 계좌번호 테이블에서 계좌번호가 100111 데이터의 관리점코드(1000)을 확인
- 관리점 코드(1000)를 관리점 테이블에 전달하여 관리점 확인(서울점)
- SQL 작성 )
SELECT A.계좌번호, B.관리점
FROM 계좌 A, 관리점 B
WHERE A.관리점코드 = B.관리점코드
AND A.계좌번호 = '100111'
● 계층형 데이터 모델
- 자기 자신끼리 관계가 발생. 즉, 하나의 엔티티 내의 인스턴스끼리 계층 구조를 가지는 경우를 뜻함
- 계층 구조를 갖는 인스턴스끼리 연결하는 조인을 셀프조인이라고 함(같은 테이블을 여러번 조인)
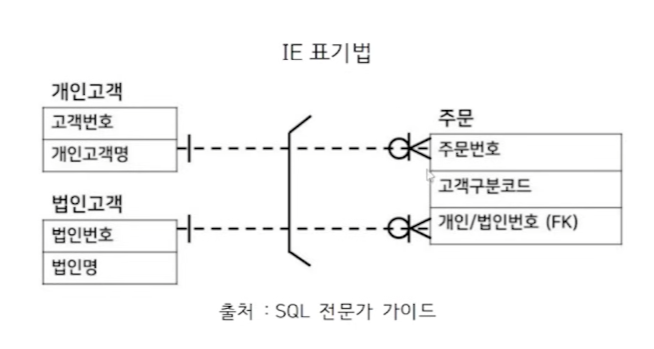
● 상호배타적 관계
- 두 테이블 중 하나만 가능한 관계를 말함
ex) 주문 엔티티에는 개인 또는 법인번호 둘 중 하나만 상속될 수 있음 => 상호배타적 관계
즉 주문은 개인 고객이거나 법인 고객 둘 중 하나의 고객만 가능
PART8. 모델이 표현하는 트랜잭션의 이해
● 트랜잭션이란
- 하나의 연속적인 업무 단위를 말함
- 트랜잭션에 의한 관계는 필수적인 관계 형태를 가짐
- 하나의 트랜잭션에는 여러 SELECT, INSERT, DELETE, UPDATE 등이 포함될 수 있음
- ※ 계좌이체를 예를 들면
A고객이 B고객에게 100만원을 이체하려고 가정할 때
1. A고객의 잔액이 100만원 이상인지 확인
2. 이상이면 A고객 잔액을 -100 UPDATE
3. B고객 잔액에 +100 UPDATE - 이 때, 2번과 3번의 과정이 동시에 수행되어야 한다. 즉, 모두 성공하거나 모두 취소되어야 함(ALL or Nothing)
=> 이런 특성을 갖는 연속적인 업무 단위를 트랜잭션이라고 한다. - ※ 주의
1. A고객의 잔액 차감과 B고객 잔액 가산이 서로 독립적으로 발생하면 안됨
-> 각각의 INSERT문으로 개발되면 안됌
2. 부분 COMMIT 불가
-> 동시 COMMIT 혹은 ROLLBACK 처리
● 필수적, 선택적 관계와 ERD
- 두 엔티티의 관계가 서로 필수적일 때 하나의 트랜잭션 형성
- 두 엔티티가 서로 독립적 수행이 가능하다면 선택적 관계로 표현
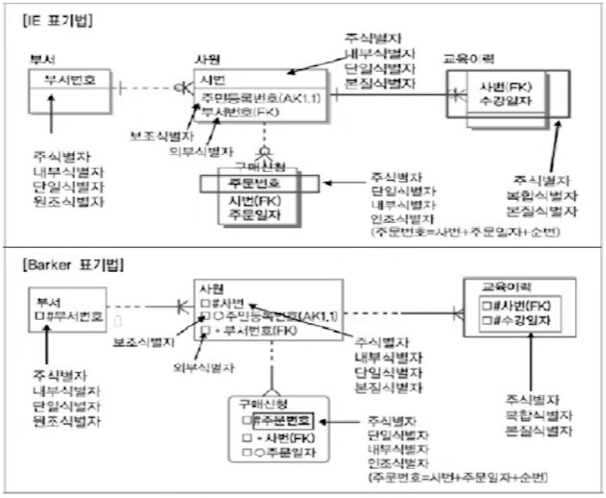
- IE 표기법
- 원을 사용하여 필수적 관계와 선택적 관계를 구분
- 필수적 관계에는 원을 그리지 않는다.
- 선택적 관계에는 관계선 끝에 원을 그린다.
- 바커 표기법
- 실선과 점선으로 구분
- 필수적 관계는 관계선을 실선으로 표기
- 선택적 관계는 관계선을 점선으로 표기
PART9. NULL 속성의 이해
● NULL 이란
- DBMS에서 아직 정해지지 않은 값을 의미
- 0과 빈 문자열('')과는 다른 개념
- 모델 설계 시 각 컬럼별로 NULL을 허용할 지 결정(Nullable Column)
● NULL의 특성
- NULL을 포함한 연산결과는 항상 NULL
- 집계함수는 NULL을 제외한 연산 결과 리턴
※ SUM, AVG, MIN, MAX 등의 함수는 항상 NULL을 무시한다.
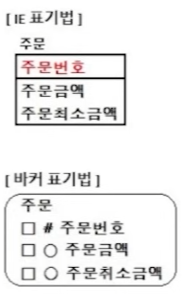
● NULL의 ERD 표기법
- IE 표기법에서는 NULL 허용 여부를 알 수 없음
- 바커 표기법에서는 속성 앞에 동그라미가 NULL 허용 속성을 의미
PART10. 본질 식별자 vs 인조 식별자
● 식별자 구분(대체 여부에 따른)
- 본질 식별자
- 업무에 의해 만들어지는 식별자(꼭 필요한 식별자)
- 인조 식별자
- 인위적으로 만들어지는 식별자(꼭 필요하진 않지만 관리의 편의성 등의 이유로 인워적으로 만들어지는 식별자)
- 본질식별자가 복잡한 구성을 가질 때 인위적으로 생성
- 주로 각 행을 구분하기 위한 기본키로 사용되며 자동으로 증가하는 일련번호 같은 형태
● 예제) 주문과 주문 상세에 대한 엔티티 설계 과정
주문이 들어오면 주문 엔티티에는 (주문번호 + 고객 번호를 저장). 이 때 PK는 주문번호
주문 상세에는 각 주문별로 어떤 상품이, 언제, 몇 개 주문됐는지 등을 기록한다.

※ 주문 상세 테이블 설계 시 다음과 같은 식별자를 고려할 수 있다.
1.PK : 주문번호 + 상품번호로 설계
- 주문을 하면 주문번호와 상품번호가 필요하므로 본질식별자(주문번호 + 상품번호)가 된다
- 하지만 PK가 (주문번호 + 상품번호)면 하나의 주문번호로 같은 상품의 주문 결과를 저장할 수 없게 된다.
- 실제로 쇼핑하다보면 동일한 장바구니에 A상품 5개를 주문했는데, 뒈어 또 다시 A상품을 3개를 추가로 주문하기도 함.

2. PK : 주문번호 + 주문순번(주문순번이라는 컬럼을 생성)
- 하나의 주문에 여러 상품에 대한 주문 결과 저장 가능 -> 주문 순번으로 인해 구분
- 매 주문마다 동일한 상품 주문 시 주문 순번을 정하기 위해 상품의 주문 횟수를 세야한다는 점이 매우 불편
즉, 사과를 총 3번 구매하였으니 주문 순번은 1,2,3 순서대로 입력되어야 함.


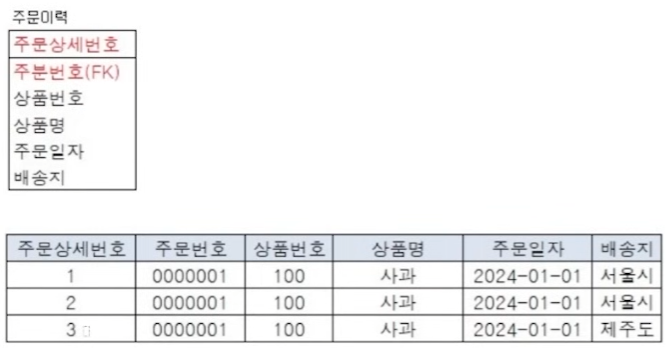
3. PK : 주문상세번호(인조식별자 생성)
- 주문상세번호로 각 주문이력을 구분하기떄문에 같은 주문의 같은 상품이력이 저장될 수 있음
- 상품상세번호만이 주식별자이므로 나머지 정보들이 중복 저장될 위험 발생
- 실제 업무와 상관없는 주문상세번호를 주식별자로 생성하면 쓸모없는 index가 생성됌(PK 생성 시 자동 unique index 생성)
- ※ 따라서 인조 식별자는 다음의 단점을 가지게 된다.
- 중복 데이터 발생 가능성 -> 데이터 품질 저하
- 불필요한 인덱스 생성 -> 저장공간 낭비 및 DML 성능 저하
- ※※ 인덱스는 원래 조회 성능을 향상시키기 위한 객체이며, 인덱스는 DML(INSERT, UPDATE, DELETE)시 INDEX SPLIT 현상으로 성능이 저하된다.